
Для одного из моих проектов понадобилось раздобыть список субъектов РФ с их гербами. Я решил автоматизировать этот процесс, написав скрипт на языке Python. Поделюсь с вами процессом разработки, трудностями, с которыми столкнулся и их решениями.
Парсить будем эту страницу – статья «Субъекты Российской Федерации»: https://ru.wikipedia.org/wiki/%D0%A1%D1%83%D0%B1%D1%8A%D0%B5%D0%BA%D1%82%D1%8B_%D0%A0%D0%BE%D1%81%D1%81%D0%B8%D0%B9%D1%81%D0%BA%D0%BE%D0%B9_%D0%A4%D0%B5%D0%B4%D0%B5%D1%80%D0%B0%D1%86%D0%B8%D0%B8
Нам понадобятся библиотеки (requests – для HTTP запросов, BeautifulSoup4 – для разбор HTML документа и lxml – нужна для BeautifulSoup4):
pip install requests lxml BeautifulSoup4
BeautifulSoup4 сам по себе не ставит парсер lxml, его мы поставили вручную.
Контент интересующей страницы нужно скачать. Чтобы не дергать сайт при каждой нашей попытке во время разработки, предлагаю скачать документ один раз и сохранить его в файл при первом запуске, а в последствии брать содержимое уже из локального файла, а не с сайта.
import requests
from bs4 import BeautifulSoup
import os
URL = 'https://ru.wikipedia.org/wiki/%D0%A1%D1%83%D0%B1%D1%8A%D0%B5%D0%BA%D1%82%D1%8B_%D0%A0%D0%BE%D1%81%D1%81%D0%B8%D0%B9%D1%81%D0%BA%D0%BE%D0%B9_%D0%A4%D0%B5%D0%B4%D0%B5%D1%80%D0%B0%D1%86%D0%B8%D0%B8'
FILE = 'wikipage.html'
def load_url_contents_cached(url, local_file):
# если есть на диске, то считаем с диска
if os.path.exists(local_file):
with open(local_file, 'r') as f:
contents = f.read()
else:
# нет на диске - скачаем
contents = requests.get(url).text
# сохраним в файл
with open(local_file, 'w') as f:
f.write(contents)
return contents
В переменной contents лежит целиком HTML код в виде текста. Превратим его в суп, т. е. в объект BeautifulSoup, который даст возможность работать с ним в форме объектной модели: искать элементы по их именам, классам и атрибутам, и извлекать их контент и свойства.
soup = BeautifulSoup(contents, 'lxml') print(soup.prettify()) # посмотреть код страницы – много текста
Далее, нам нужно понять, что искать на странице. Мне нужна таблица с регионами и скачать их гербы. Листаем до таблицы, выбираем название первого субъекта, правая кнопка, посмотреть код. Да, сразу скажу, что использую браузер Chrome.
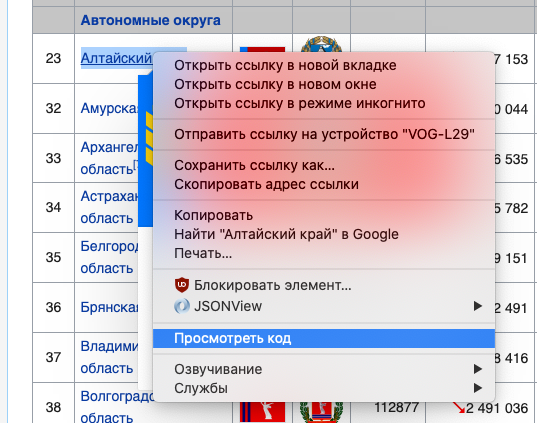
Находим в открывшейся консоли разработчика нужный элемент с названием региона, снова правой кнопкой – Copy – Copy selector. Это копирует селектор (строку, которая позволяет однозначно выбрать именно этот элемент страницы) в буфер обмена.
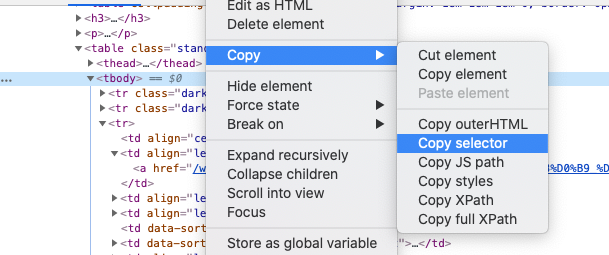
Теперь по селектору BS4 может найти нам элемент:
elem = soup.select('#mw-content-text > div > table.standard.sortable.jquery-tablesorter > tbody > tr:nth-child(3) > td:nth-child(2) > a')
print(elem) # []
Увы, пусто. Давайте откроем код страницы, чтобы посмотреть, что не так. Оказывается при загрузке у таблицы нет класса jquery-tablesorter. Он добавляется уже во время исполнения кода JS:

А мы парсим просто HTML пришедший с сервера и не запускаем никакие скрипты на страницы. Поэтому удаляем этот лишний класс из селектора:
elem = soup.select('#mw-content-text > div > table.standard.sortable > tbody > tr:nth-child(3) > td:nth-child(2) > a')
print(elem)
# [<a href="/wiki/%D0%90%D0%B4%D1%8B%D0%B3%D0%B5%D1%8F" title="Адыгея">Республика Адыгея</a>]
Теперь элемент успешно обнаруживается. Но мы разобьем этот запрос на части, чтобы сначала извлечь все строки таблицы, а затем из каждой строки достать название и ссылку. Изучим, как нам достать путь к картинге герба из каждой строки таблицы tr:

Можно было бы взять атрибут src от img, но в атрибуте srcset есть варианты побольше размером, однако его придется тоже разобрать на части – разбить сначала по запятым, потом по пробелам.
Обратите внимание, что селектор всегда возвращает нам массив элементов, даже если элемент внутри всего один такой, поэтому после select всегда обращаемся по индексу. Атрибут у элемента тоже берут через квадратные скобки.
def extract_names_and_image_urls(contents):
soup = BeautifulSoup(contents, 'lxml')
# строки таблицы
rows = soup.select('#mw-content-text > div > table.standard.sortable > tbody > tr')
for row in rows:
# все ячейки этой строки
columns = row.select('td')
try:
# название региона - это содержание нулевого по счету тэга "a" в ячейке номер 1
name = columns[1].select('a')[0].text.strip()
# а картинка в 3 ячейке в тэге img возьмем атрибут srcset
image_page_url: str = columns[3].select('img')[0]['srcset']
# разбить атрибут по запятым, взять последний вариант, потом забить по пробелам, взять адрес
# и добавить протокол к нему, чтобы иметь полный URL
large_image = 'https:' + image_page_url.split(',')[-1].strip().split(' ')[0]
yield name, large_image
except IndexError:
continue
Если не понимаете, что именно происходит, то запустите этот код и увидите по шагам, как мы достаем данные из тэгов:
def separator(double=False):
"""Разделительная линия"""
print('-' * 100)
if double:
print()
separator()
contents = load_url_contents_cached(URL, FILE)
soup = BeautifulSoup(contents, 'lxml')
# строки таблицы
rows = soup.select('#mw-content-text > div > table.standard.sortable > tbody > tr')
# 42 строка
row = rows[42]
print(row)
separator()
columns = row.select('td')
print(columns)
separator()
print(columns[1])
separator()
print(columns[1].select('a'))
separator()
print(columns[1].select('a')[0])
separator()
print(columns[1].select('a')[0].text)
separator(double=True)
print(columns[3])
separator()
print(columns[3].select('img'))
separator()
print(columns[3].select('img')[0])
separator()
print(columns[3].select('img')[0]['srcset'])
separator()
image_page_url = columns[3].select('img')[0]['srcset']
print(image_page_url.split(','))
separator()
print(image_page_url.split(',')[-1])
separator()
print(image_page_url.split(',')[-1].strip().split(' '))
separator()
print(image_page_url.split(',')[-1].strip().split(' ')[0])
separator()
print('https:' + image_page_url.split(',')[-1].strip().split(' ')[0])
Полученные картинки нужно только скачать:
def download_file(url, save_to):
r = requests.get(url, allow_redirects=True)
with open(save_to, 'wb') as f:
f.write(r.content)
Собираем все вместе. Качаем страницу, читаем список имен и адресов, создаем папку для картинок, качаем каждый герб и сохраняем его под именем субъекта:
data = extract_names_and_image_urls(load_url_contents_cached(URL, FILE))
IMAGE_PATH = 'out_img'
os.makedirs(IMAGE_PATH, exist_ok=True) # создать папку, если ее нет
for name, image_url in data:
print(f'Downloading {name}')
download_file(image_url, os.path.join(IMAGE_PATH, name + '.png'))
Вот что у меня сохранилось в итоге:

Специально для канала @pyway. Подписывайтесь на мой канал в Телеграм @pyway 👈





