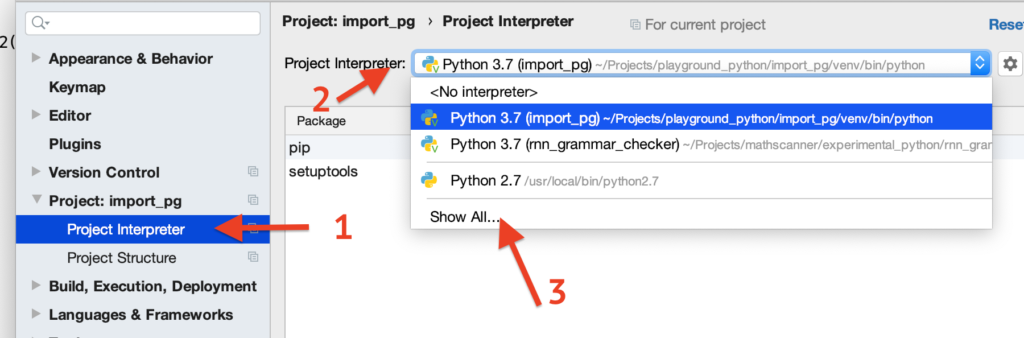
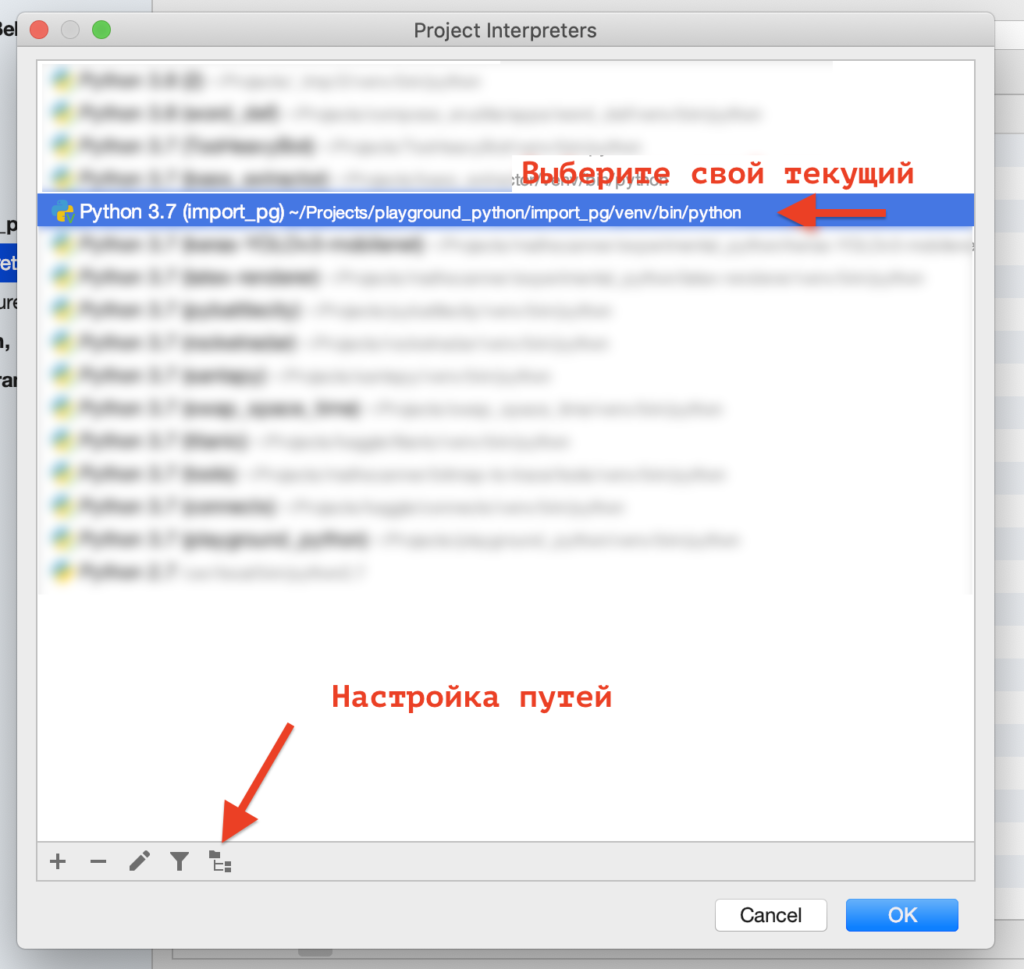
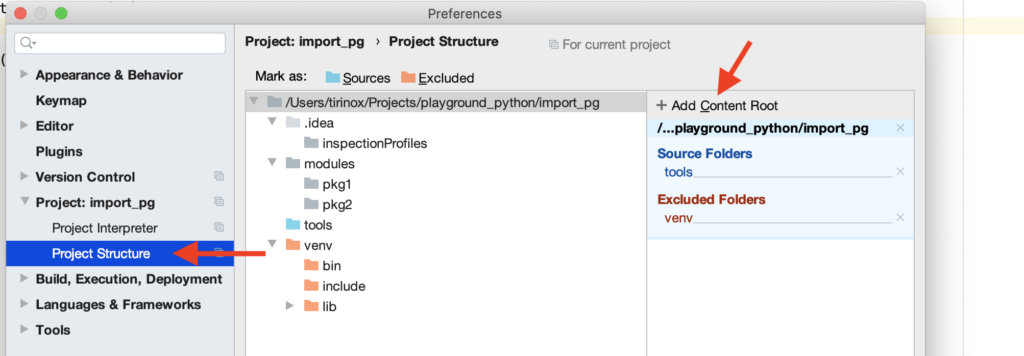
Недавно мы обсуждали расчет расстояния Левеншейна, настало время испытать его применение на практике. Библиотека FuzzyWuzzy содержит набор функций для нечеткого поиска строк, дедупликации (удаления копий), корректировки ошибок. Она позволяет стать поиску умнее, помогая преодолеть влияние человеческого фактор.
Начнем с установки:
pip install fuzzywuzzy python-Levenshtein
Модуль python-Levenshtein можно устанавливать по желанию: работать будет и без него, но с ним гораздо быстрее (в разы). Поэтому советую его установить, он мелкий, порядка 50 Кб.
Похожесть двух строк
Задача: есть две строки, требуется вычислить степень их похожести числом от 0 до 100. В FuzzyWuzzy для этого есть несколько функций, отличающихся подходом к сравнению и вниманием к деталям. Не забудем импортировать:
from fuzzywuzzy import fuzz
Функция fuzz.ratio – простое посимвольное сравнение. Рейтинг 100 только если строки полностью равны, любое различие уменьшает рейтинг, будь то знаки препинания, регистр букв, порядок слов и так далее:
>>> fuzz.ratio("я люблю спать", "я люблю спать")
100
>>> fuzz.ratio("я люблю спать", "Я люблю cпать!")
81
>>> fuzz.ratio("я люблю спать", "я люблю есть")
88
Обратите внимание, что рейтинг второго примера ниже, чем у третьего, хотя по смыслу должно быть наоборот.
Следующая функция fuzz.token_sort_ratio решает эту проблему. Теперь акцент именно на сами слова, игнорируя регистр букв, порядок слов и даже знаки препинания по краям строки.
>>> fuzz.token_sort_ratio("я люблю спать", "я люблю есть")
56
>>> fuzz.token_sort_ratio("я люблю спать", "Я люблю спать!")
100
>>> fuzz.token_sort_ratio("я люблю спать", "спать люблю я...")
100
>>> fuzz.token_sort_ratio("Мал да удал", "удал да МАЛ")
100
>>> fuzz.token_sort_ratio("Мал да удал", "Да Мал Удал")
100
Однако, смысл пословицы немного изменился, а рейтинг остался на уровне полного совпадения.
Функция fuzz.token_set_ratio пошла еще дальше: она игнорирует повторяющиеся слова, учитывает только уникальные.
>>> fuzz.token_set_ratio("я люблю спать", "люблю я спать, спать, спать...")
100
>>> fuzz.token_set_ratio("я люблю спать", "люблю я спать, спать и спать...")
100
>>> fuzz.token_set_ratio("я люблю спать", "но надо работать")
28
# повторы в token_sort_ratio роняют рейтинг!
>>> fuzz.token_sort_ratio("я люблю спать", "люблю я спать, спать и спать.")
65
# но вот это странно:
>>> fuzz.token_set_ratio("я люблю спать", "люблю я спать, но надо работать")
100
>>> fuzz.token_set_ratio("я люблю спать", "люблю я спать, люблю я есть")
100
Последние два примера вернули 100, хотя добавлены новые слова, и это странно. Тут следует вспомнить о fuzz.partial_ratio, которая ведет себя также. А именно, проверяет вхождение одной строки в другую. Лишние слова игнорируются, главное – оценить, чтобы ядро было одно и тоже.
>>> fuzz.partial_ratio("одно я знаю точно", "одно я знаю")
100
>>> fuzz.partial_ratio("одно я знаю точно", "одно я знаю!")
92
>>> fuzz.partial_ratio("одно я знаю точно", "я знаю")
100
Еще еще более навороченный метод fuzz.WRatio, который работает ближе к человеческой логике, комбинируя несколько методов в один алгоритм в определенными весами (отсюда и название WRatio = Weighted Ratio).
>>> fuzz.WRatio("я люблю спать", "люблю Я СПАТЬ!")
95
>>> fuzz.WRatio("я люблю спать", "люблю Я СПАТЬ и есть")
86
>>> fuzz.WRatio("я люблю спать", "!!СПАТЬ ЛЮБЛЮ Я!!")
95
Нечеткий поиск
Задача: найти в списке строк одну или несколько наиболее похожих на поисковый запрос.
Импортируем подмодуль и применим process.extract или process.extractOne:
from fuzzywuzzy import process
strings = ['привет', 'здравствуйте', 'приветствую', 'хай', 'здорова', 'ку-ку']
process.extract("Прив", strings, limit=3)
# [('привет', 90), ('приветствую', 90), ('здравствуйте', 45)]
process.extractOne("Прив", strings)
# ('привет', 90)
Удаление дубликатов
Очень полезная функция для обработки данных. Представьте, что вам досталась 1С база номенклатуры запчастей, там полный бардак, и вам нужно поудалять лишние повторяющиеся позиции товара, но где-то пробелы лишние, где-то буква перепутана и тому подобное. Тут пригодится process.dedupe.
dedupe(contains_dupes, threshold=70, scorer=token_set_ratio)Первый аргумент – исходный список, второй – порог исключения (70 по умолчанию), третий – алгоритм сравнения (token_set_ratio по умолчанию).
Пример:
arr = ['Гайка на 4', 'гайка 4 ГОСТ-1828 оцинкованная', 'Болты на 10', 'гайка 4 ГОСТ-1828 оцинкованная ...', 'БОЛТ'] print(list(process.dedupe(arr))) # ['гайка 4 ГОСТ-1828 оцинкованная ...', 'Болты на 10', 'БОЛТ']
FuzzyWuzzy можно применять совместно с Pandas. Например так (без особых подробностей):
def get_ratio(row):
name = row['Last/Business Name']
return fuzz.token_sort_ratio(name, "Alaska Sea Pilot PAC Fund")
df[df.apply(get_ratio, axis=1) > 70]
Специально для канала @pyway. Подписывайтесь на мой канал в Телеграм @pyway 👈