
Генераторы случайных чисел (аббр. ГСЧ или RNG) можно разделить на псевдослучайные генераторы (pseudo random number generator – PRNG) и настоящие генераторы (true random number generator – TRNG). Настоящие случайное число может быть получено, например, честным бросанием (без мухлежа) игрального кубика. Но, цифровая техника, в т.ч. и компьютер — вещь точная и детерминированная. И нет так очевидно, где нам там брать случайные числа. Да, бывают аппаратные ГСЧ, построенные на аналоговых шумах или квантовых эффектах, но они не всегда доступны простым пользователям. Однако математики разработали алгоритмы, по которым можно с помощью простых и точных операций (типа сложения и деления) получать «иллюзию» случайности.
Давайте для начала рассмотрим линейный конгруэнтный метод и попробуем сконструировать свой рандом. Все начинается с зерна (seed). x[0] = seed. Следующие случайное число будет равно x[i + 1] = (a * x[i] + b) mod c. Каждое из них будет в пределах [0..c). Вот реализация:
class MyRandom:
def __init__(self, seed=42):
self._state = seed
def random(self):
self._state = (5 * self._state + 9) % 17
return self._state
r = MyRandom(42)
print([r.random() for _ in range(10)])
# [15, 16, 4, 12, 1, 14, 11, 13, 6, 5]
r2 = MyRandom(24)
print([r2.random() for _ in range(10)])
# [10, 8, 15, 16, 4, 12, 1, 14, 11, 13]
r3 = MyRandom(42)
print([r3.random() for _ in range(10)])
# [15, 16, 4, 12, 1, 14, 11, 13, 6, 5]Первое. Последовательности кажутся случайными, но на самом деле качество их невелико. Через некоторые время числа начинают повторятся. Последовательность периодична. Второе. Наш псевдослучайный генератор выдает одинаковые последовательности для одинаковых seed. Алгоритм детерминирован. Последнее свойство бывает вредно и полезно. Представим, что вы проводите эксперимент. Допустим, учите нейросеть. Инициализировав веса случайными числами, вы получаете какой-то результат. Далее вы меняете что-то в архитектуре сети и запускаете снова, и получаете иной результат. Но как убедиться, повлияли ли ваши изменения в коде, или просто иная случайная инициализация изменила результат. Имеет смысл зафиксировать seed генератора случайных чисел константой в начале программы. При следующем запуске мы получим точно такую же инициализацию сети, как и в предыдущем.
Но, если мы не хотим повторяемости, то можно инициализировать генератор какой-то меняющейся от запуска к запуску переменной (например, временем):
import time
r4 = MyRandom(int(time.time()))
print([r4.random() for _ in range(10)])
# [3, 7, 10, 8, 15, 16, 4, 12, 1, 14]Для получение случайных величин в Python есть несколько способов. Мы рассмотрим следующие:
• Встроенный модуль random
• numpy.random из библиотеки NumPy
• Функцию os.urandom
• Встроенный модуль secrets
• Встроенный модуль uuid
Модуль random
Самый популярный вариант: модель встроенный random. Модуль random предоставляет набор функций для генерации псевдослучайных чисел. Реализована генерация на языке Си (исходник) по более хитрому алгоритму «вихрь Мерсенна», разработанному в 1997 году. Он дает более «качественные» псевдослучайные числа. Но они по-прежнему получается из начального зерна (seed) путем совершения математических операций. Зная seed и алгоритм можно воспроизвести последовательность случайных чисел; более того существуют алгоритмы позволяющие вычислить из последовательности чисел ее seed. Поэтому такие алгоритмы не пригодны для генерации конфиденциальных данных: паролей, и ключей доступа. Но он вполне сгодится для генерации случайностей в играх (не азартных) и прочих приложений, где не страшно, если кто-то сможет воспроизвести и продолжить последовательностей случайных чисел. Воспроизводимость случайностей поможет вам в задачах статистики, в симуляциях различных процессов.
Приступим:
>>> import randomrandom.seed(new_seed) – сброс ГСЧ с новым seed:
>>> random.seed(4242)
>>> random.random()
0.8624508153567833
>>> random.random()
0.41569372364698065
>>> random.seed(4242)
>>> random.random()
0.8624508153567833
>>> random.random()
0.41569372364698065Когда мы второй раз задали тот же seed, ГСЧ выдает точно такие же случайные числа. Если мы не задаем seed, то ГСЧ будет скорее всего инициализирован системным временем, и значения будут отличаться от запуска к запуску.
random.randint(a, b) – случайное целое число от a до b (включительно):
>>> random.randint(5, 8)
5
>>> [random.randint(5, 8) for _ in range(10)]
[6, 8, 5, 8, 6, 6, 8, 5, 5, 6]random.randrange(a, b, step) – случайное целое число от a до b (не включая b) с шагом step. Аргументы имеют такой же смысл, как у функции range. Если мы зададим только a, получим число в [0, a) с шагом 1; если задаем a и b, то в число будет в диапазоне [a, b):
>>> [random.randrange(10) for _ in range(5)]
[9, 3, 7, 0, 4]
>>> [random.randrange(10, 20) for _ in range(5)]
[15, 10, 15, 12, 18]
>>> [random.randrange(10, 20, 2) for _ in range(5)]
[14, 14, 18, 16, 16]random.choice(seq) – выбирает из последовательности seq случайный элемент. Последовательность должна иметь длину (len). Например list, tuple, range – подойдут, а произвольные генераторы – нет.
>>> alist = [1, 2, 3, 4, 5, 6]
>>> random.choice(alist)
5
>>> random.choice(alist)
3
>>> random.choice(alist)
1random.choices(population, weights=None, *, cum_weights=None, k=1) – позволяет выбрать k элементов из population. Выбранные элементы могут повторяться. Можно задать веса каждого элемента через weight, или кумулятивные веса через cum_weights. Веса определяют вероятность соответствующего элемента быть выбранным. Если мы не задали никакие веса, то любой элемент считается равновероятным. Кумулятивные веса – это значит, каждый следующий вес является суммой предыдущего и некоторой добавки, которая и есть вес соответствующего элемента. Пример: weights=[10, 5, 30, 5] эквивалентно cum_weights=[10, 15, 45, 50], причем последний вариант предпочтительнее, так как с кумулятивными весами функция работает быстрее.
>>> random.choices([1, 2, 3], k=10)
[1, 3, 1, 1, 2, 2, 1, 3, 3, 1]📎 Пример. Выбор с весами (80% шанс получить 1, 15% для 2 и 5% для 3):
>>> random.choices([1, 2, 3], k=10, weights=[80, 15, 5])
[1, 1, 1, 1, 2, 1, 3, 1, 1, 1]📎 Пример. Генерация случайной строки:
>>> import string
>>> ''.join(random.choices(string.ascii_letters, k=10))
'ncNAzTldvg'random.shuffle(x) – перемешивает саму последовательность x, ничего не возвращает.
>>> x = [10, 20, 30, 40]
>>> random.shuffle(x)
>>> x
[10, 40, 20, 30]
>>> random.shuffle(x)
>>> x
[20, 30, 10, 40]Если последовательность неизменяема (например, кортеж), то используйте random.sample(x, k=len(x)), которая вернет перемешанный список, не трогая исходную последовательность.
>>> random.sample(x, k=len(x))
[40, 30, 10, 20]random.random() – случайное вещественное число от 0.0 до 1.0, не включая 1.0, т.е. в диапазоне [0, 1). Равновероятное распределение.
>>> random.random()
0.8505907349159074
>>> random.random()
0.49760476981102786random.uniform(a, b) – случайное вещественное число на промежутке [a, b], равноверотяно.
>>> random.uniform(5, 7)
6.812839982463059
>>> random.uniform(5, 7)
6.564395491702289
>>> random.uniform(5, 7)
5.875898672403455random.gauss(mu, sigma) и random.normalvariate(mu, sigma) – нормальные распределения с медианой μ и с среднеквадратичным отклонением σ .
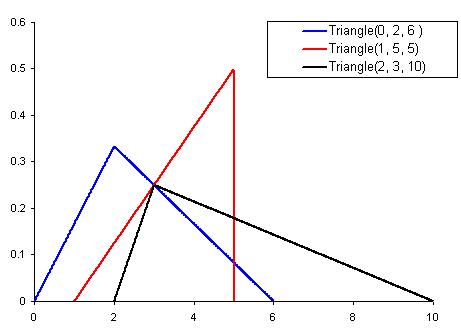
random.triangular(low, high, mode) – треугольное разпределние от low до high с модой mode ∈ [low, high].
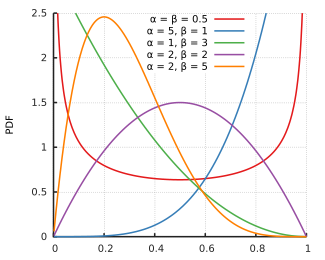
random.betavariate(alpha, beta) – бета-распределение.
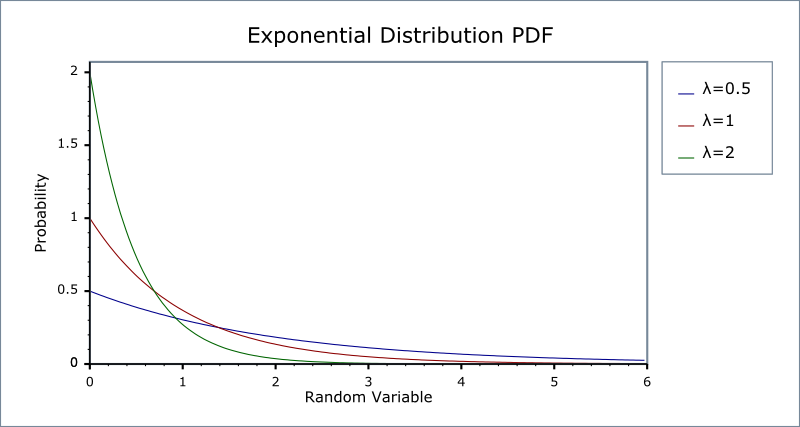
random.expovariate(lambd) – экспоненциальное распределение.
random.gammavariate(alpha, beta) – гамма-распределение (не путать с гамма-функцией).
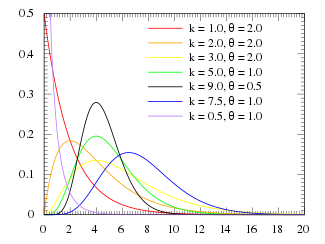
random.lognormvariate(mu, sigma) – логнормальное распределение. Если случайная величина имеет логнормальное распределение, то её логарифм имеет нормальное распределение.
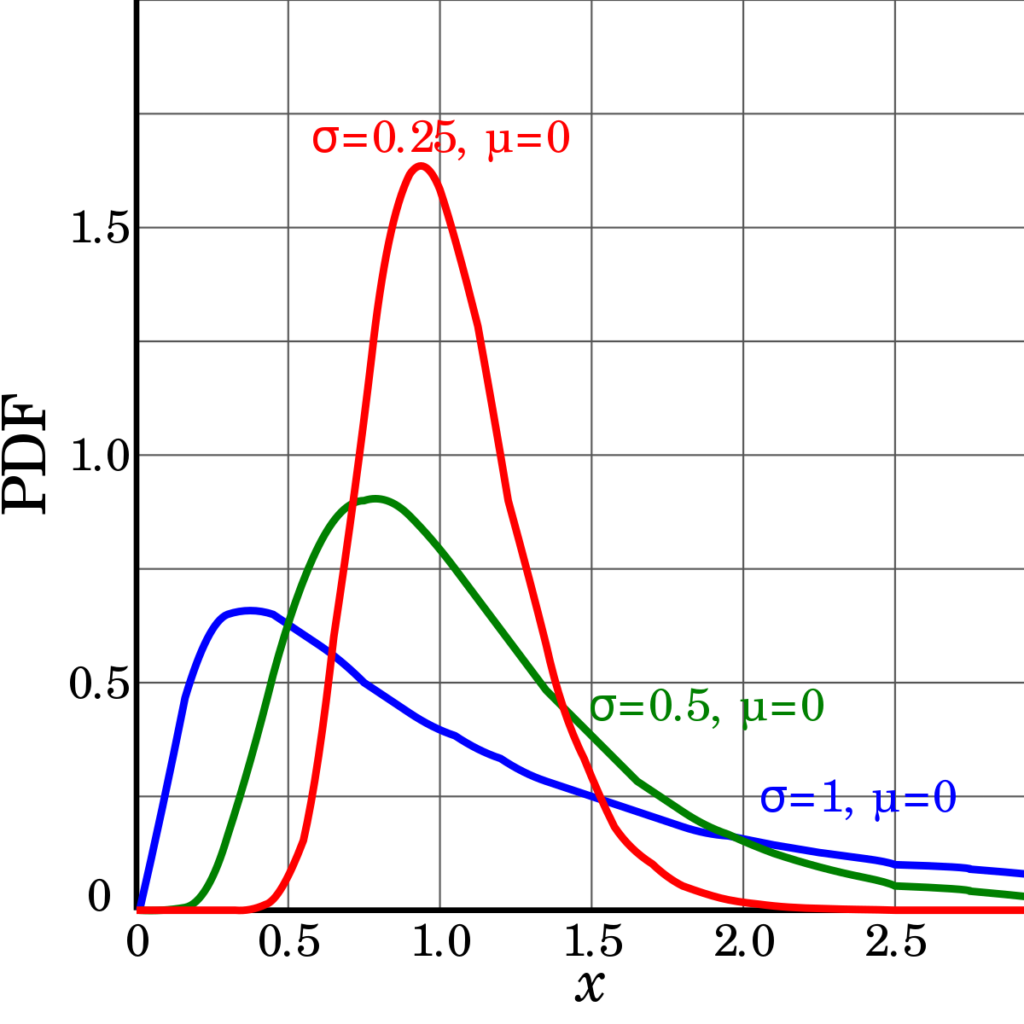
random.vonmisesvariate(mu, kappa) – распределение вон Мизеса (также известное как круглое нормальное распределение или распределение Тихонова) является непрерывным распределением вероятности на круге.
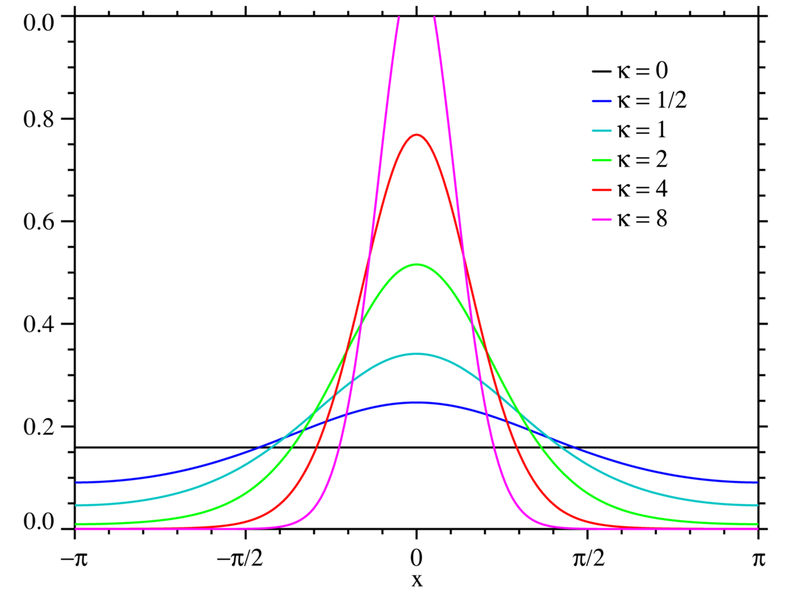
random.paretovariate(alpha) – распределение Парето.
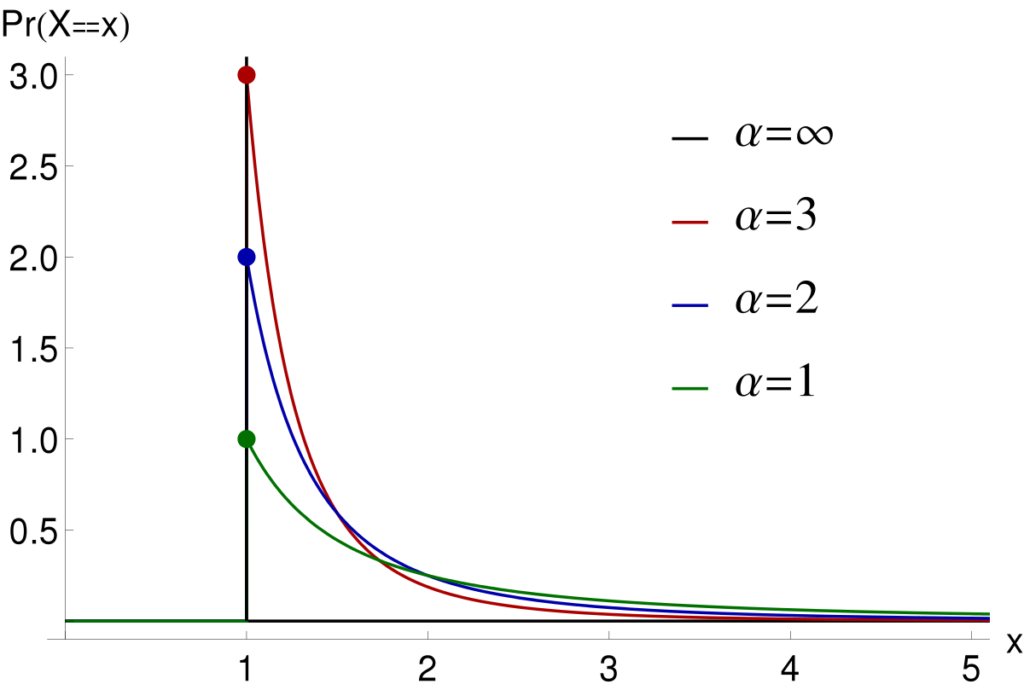
random.weibullvariate(alpha, beta) – распеделение Вейбулла.
Внутри модуля random скрывается класс Random. Можно создавать экземпляры этого класса, которые не будут делить состояние с остальными функциями random. Этот класс содержит методы с аналогичными названиями, что и функции модуля:
>>> my_random = random.Random(42)
>>> my_random.normalvariate(1, 2.5)
1.6133158542696586
>>> my_random.random()
0.27502931836911926
>>> my_random.choice([1, 2, 3])
1Класс Random пригодится вам, если нужна гарантированная воспроизводимость случайных чисел, ведь из этого ГСЧ только вы берете случайные числа, и никакая более часть программы не нарушит эту последовательность.
Класс random.SystemRandom() – альтернативные класс для случайных чисел, который берет случайные числа не из встроенного алгоритма, а из системного os.urandom, о котором будет рассказано в конце статьи.
Случайные числа в библиотеке NumPy
ГСЧ из NumPy пригодится на случай необходимости генерации случайных многомерных массивов.
numpy.random.seed(n) – задать seed для ГСЧ.
rand(d0, d1, …, dn) – многомерный массив случайных вещественных чисел в диапазоне [0, 1). Размерности указываются через запятую.
>>> import numpy as np
>>> np.random.rand(3, 2)
array([[0.10249247, 0.21503386],
[0.40189789, 0.23972727],
[0.28861301, 0.12995166]])randn(d0, d1, …, dn) – тоже, что и rand, но случайные числа будут распределены нормально вокруг 0 со СКО = 1.
>>> np.random.randn(3, 2)
array([[ 1.13506644, 1.1115104 ],
[-0.43613352, -0.03630799],
[ 0.69787228, 1.24875159]])randint(low[, high, size, dtype]) – случайные целые числа в диапазоне [low, high) в многомерном массиве размера size (целое число или кортеж размерностей).
>>> np.random.randint(10, 20, 5)
array([18, 18, 10, 19, 15])
>>> np.random.randint(10, 20, (3, 2))
array([[10, 13],
[12, 14],
[19, 14]])random_integers(low[, high, size]) – случайные целые числа в диапазоне [low, high] в многомерном массиве размера size (целое число или кортеж размерностей).
>>> np.random.random_integers(10, 20, (3, 2))
array([[10, 20],
[16, 14],
[12, 18]])randint никогда не возвращает верхнюю границу диапазона (high), random_integers – может вернуть и high.
random_sample([size]), random([size]), ranf([size]), sample([size]) – эти четыре функции называются по-разному, но делают одно и тоже. Возвращают многомерный массив случайных вещественных чисел в диапазоне [0, 1). Размерности указываются числом для 1D массива или кортежем для массива большего ранга.
>>> np.random.ranf(3)
array([0.60612404, 0.04881742, 0.17121467])
>>> np.random.sample(4)
array([0.71248954, 0.8613707 , 0.72469335, 0.62528553])
>>> np.random.random_sample((3, 4))
array([[0.39140157, 0.17538846, 0.55895275, 0.58363394],
[0.52779193, 0.90067421, 0.63571978, 0.62386877],
[0.52287003, 0.49077399, 0.57247767, 0.15221763]])numpy.random.choice(a, size=None, replace=True, p=None) – случайно выбирает из 1D массива один и несколько элементов.
a – одномерный массив или число. Если вместо массива – число, то оно будет преобразовано в np.arange(a).
size – размерность возвращаемой величины. По умолчанию size=None, дает один единственный элемент, если size – целое число, то вернется 1D-массив, если size — кортеж, то вернется массив размерностей из этого кортежа.
replace – допускается ли повтор элементов, т.е. «возвращаем ли мы выбранный шар обратно в корзину». По умолчанию – да. Если мы запретим возврат, то мы не сможем извлечь больше элементов, чем есть в исходном массиве.
p – массив вероятностей для каждого элемента быть выбранным. Если не задано, распределение вероятностей равномерно.
📎 Пример. Допуская повторы:
>>> np.random.choice([1, 2, 3, 4], 3)
array([1, 3, 3])📎 Пример. Не допуская повторы:
>>> np.random.choice([1, 2, 3, 4], 3, replace=False)
array([1, 3, 4])📎 Пример. Задаем вероятности:
>>> np.random.choice([1, 2, 3, 4], 4, p=[0.1, 0.7, 0.0, 0.2])
array([2, 2, 1, 2])📎 Пример. Выбор строк:
>>> np.random.choice(["foo", "bar", "dub"])
'dub'
>>> np.random.choice(["foo", "bar", "dub"], size=[2, 2])
array([['bar', 'bar'],
['bar', 'dub']], dtype='<U3')bytes(length) – возвращает length случайных байт.
>>> np.random.bytes(10)
b'\x19~\xd0w\xc2\xb6\xe5M\xb1R'shuffle(x) и permutation(x) – перемешивают последовательность x. shuffle модифицирует исходную последовательность, а permutation – возвращает новую перемешанную последовательность, не трогая исходную.
>>> x = np.arange(10)
>>> x
array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
>>> np.random.shuffle(x)
>>> x
array([8, 6, 0, 3, 1, 2, 4, 9, 7, 5])
>>> y = np.random.permutation(x)
>>> y
array([4, 8, 7, 5, 9, 3, 6, 0, 2, 1])
>>> x
array([8, 6, 0, 3, 1, 2, 4, 9, 7, 5])Также в NumPy имеется еще более богатый выбор различных распределений случайных величин, чем у обычного random. Не будет подробно останавливаться на каждой функции, так как это уже больше статистика, чем программирование. Из названия функций легко понять, какое распределение они представляют. Главная особенность, что у каждый из этих функций есть аргумент size – кортеж размерностей возвращаемого многомерного массива или целое число, если нужен одномерный массив:
- beta(a, b[, size])
- binomial(n, p[, size])
- chisquare(df[, size])
- dirichlet(alpha[, size])
- exponential([scale, size])
- f(dfnum, dfden[, size])
- gamma(shape[, scale, size])
- geometric(p[, size])
- gumbel([loc, scale, size])
- hypergeometric(ngood, nbad, nsample[, size])
- laplace([loc, scale, size])
- logistic([loc, scale, size])
- lognormal([mean, sigma, size])
- logseries(p[, size])
- multinomial(n, pvals[, size])
- multivariate_normal(mean, cov[, size, …)
- negative_binomial(n, p[, size])
- noncentral_chisquare(df, nonc[, size])
- noncentral_f(dfnum, dfden, nonc[, size])
- normal([loc, scale, size])
- pareto(a[, size])
- poisson([lam, size])
- power(a[, size])
- rayleigh([scale, size])
- standard_cauchy([size])
- standard_exponential([size])
- standard_gamma(shape[, size])
- standard_normal([size])
- standard_t(df[, size])
- triangular(left, mode, right[, size])
- uniform([low, high, size])
- vonmises(mu, kappa[, size])
- wald(mean, scale[, size])
- weibull(a[, size])
- zipf(a[, size])
📎 Пример. Генерация двух коррелирующих временных рядов из двумерного нормального распределения (multivariate_normal):
import numpy as np
import matplotlib.pyplot as plt
def corr2cov(p: np.ndarray, s: np.ndarray) -> np.ndarray:
"""Ковариационная матрица от корреляции и стандартных отклонений"""
d = np.diag(s)
return d @ p @ d
# Начало с корреляционной матрицы и стандартных отклонений
# 0.9 это корреляция между А и B, а корреляция
# самой переменной равна 1.0
corr = np.array([[1., 0.9],
[0.9, 1.]])
stdev = np.array([3., 1.])
mean = np.array([5., -5.])
cov = corr2cov(corr, stdev)
# `size` это длина временных рядов для 2д данных
data = np.random.multivariate_normal(mean=mean, cov=cov, size=5000)
x, y = data.T
f, (ax1, ax2) = plt.subplots(1, 2)
ax1.plot(x, y, 'x')
ax2.plot(x[:100])
ax2.plot(y[:100])
plt.show()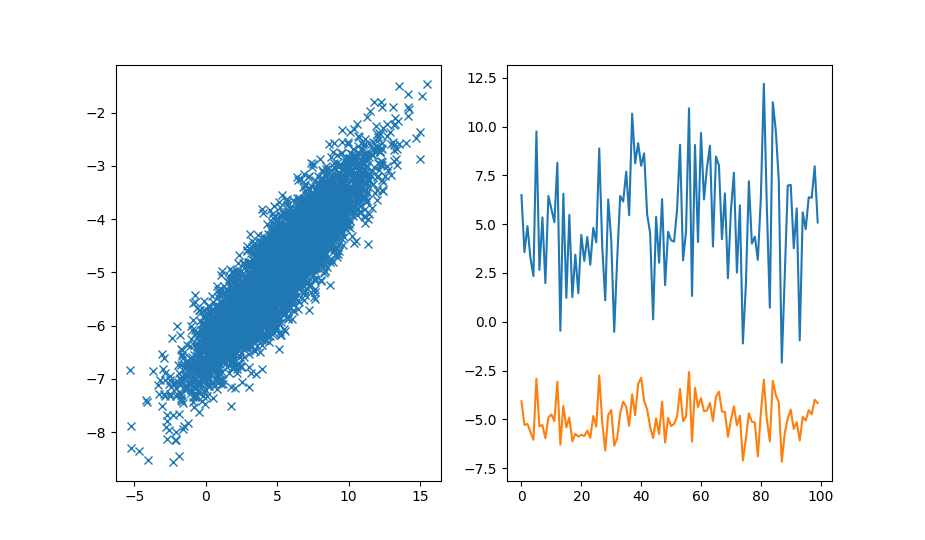
Криптографически безопасный ГСЧ
Криптографически безопасный ГСЧ (КБГСЧ) – по-прежнему псевдослучайный и детерминированный генератор, однако он использует широкий набор источников энтропии в системе. Энтропия – мера неопределенности, хаотичности системы. Случайности могут быть получены из
- Различных системных идентификаторов
- Времен возникновения разных системных событий в ядре и драйверах
- Движения мыши, нажатия клавиш и т.п.
- Аппаратный ГСЧ, например встроенный в процессоры Intel Ivy Bridge.
КБГСЧ в Python базируется на функции os.urandom(), которая в свою очередь использует:
- Чтение из /dev/urandom на Unix-like системах.
- CryptGenRandom() функцию на Windows.
Для os.urandom нет понятия seed. Последовательность случайных байт не должна быть воспроизводима. Аргумент функции – число случайных байт.
📎 Пример.
>>> import os
>>> x = os.urandom(10)
# объект типа bytes
>>> x
b'\xf0\xba\xf8\x86\xb6\xc4Aa*\xe7'
# тоже самое как 16-ричная строка
>>> x.hex()
'f0baf886b6c441612ae7'
# тоже самое как список чисел
>>> list(x)
[240, 186, 248, 134, 182, 196, 65, 97, 42, 231]В стандартной библиотеке Python несколько модулей используют функцию os.urandom:
- random.SystemRandom() – все функции обычного Random, но источник случайностей – os.urandom
- модуль secrets – удобства для генерации случайных токенов, ключей и т.п.
- uuid – генерация токенов по стандарту UUID (Universally Unique IDentifier)
Модуль secrets
По сути – обертка над os.urandom.
- secrets.token_bytes – тоже самое, что и os.urandom (по умолчанию, если размер не указан дает 32 байта).
- secrets.token_hex – тоже самое, только возвращает 16-ричную строку.
- secrets.token_urlsafe – случайная строка, пригодная для URL адресов.
- secrets.choice – безопасная версия random.choice
📎 Пример. Укоротитель ссылок:
from secrets import token_urlsafe
DATABASE = {}
def shorten(url: str, nbytes: int = 5) -> str:
token = token_urlsafe(nbytes=nbytes)
if token in DATABASE:
# если уже есть такая ссылка – генерируем еще одну рекурсивно
return shorten(url, nbytes=nbytes)
else:
DATABASE[token] = url
return 'https://bit.ly/' + token
print(shorten('https://google.com'))
print(shorten('https://yandex.ru'))
# https://bit.ly/vZ1VZug
# https://bit.ly/x966uWIСсылки в примеры получились длиннее (7 символов), чем мы просили (5 байт). Это объясняется тем, что внутри token_urlsafe использует кодировку base64, где каждый символ представляет 6 бит данных; чтобы закодировать 5 * 8 = 40 бит, понадобилось как минимум 7 6-битных символов (7 * 6 = 42 бита).
Модуль uuid
UUID (Universally Unique IDentifier) – универсальный уникальный идентификатор, уникальность которого «гарантирована» в пространстве и времени. Имеет длину 128 бит (16 байт). Наиболее интересен для нас вариант uuid4, так как он использует случайность из os.random.
>>> uuid.uuid4()
UUID('cd955a9e-445d-47de-95e2-3d8de8c61696')
>>> u = uuid.uuid4()
>>> u
UUID('7dfb1170-af20-4218-9b76-bc4d7ae6a309')
>>> u.hex
'7dfb1170af2042189b76bc4d7ae6a309'
>>> u.bytes
b'}\xfb\x11p\xaf B\x18\x9bv\xbcMz\xe6\xa3\t'
>>> len(u.bytes)
16Вероятность коллизии (вероятность получить два одинаковых uuid4) крайне мала. Если бы мы каждую секунду генерировали по одному миллиарду uuid, то через 100 лет едва ли обнаружился хоть один дубликат.
Производительность
Резонный вопрос: почему бы не использовать random.SystemRandom() (или os.urandom) везде, где можно?
Оказывается, есть существенное препятствие. Пул энтропии КБГСЧ ограничен. Если он исчерпан, то придется подождать, пока он заполнится вновь. Проведем небольшой бенчмарк на пропускную способность генераторов случайных чисел:
import random
import timeit
r_secure = random.SystemRandom()
r_common = random.Random()
n_bits = 1024
def prng():
r_common.getrandbits(n_bits)
def csprng():
r_secure.getrandbits(n_bits)
setup = 'import random; from __main__ import prng, csprng'
if __name__ == '__main__':
number = 50000
repeat = 10
data_size_mb_bytes = number * repeat * n_bits / (8 * 1024**2)
for f in ('prng()', 'csprng()'):
best_time = min(timeit.repeat(f, setup=setup, number=number, repeat=repeat))
speed = data_size_mb_bytes / best_time
print('{:10s} {:0.2f} mb/sec random throughput.'.format(f, speed))Результаты:
prng() 1794.74 mb/sec random throughput.
csprng() 94.13 mb/sec random throughput.
Почти в 20 раз обычный ГСЧ быстрее, чем КБГСЧ.
Вывод: нужна безопасность – обязательно используем secrets, random.SystemRandom, uuid.uuid4 или просто os.urandom, а если нужно много и быстро генерировать неконфиденциальные случайные данные – random и numpy.random.
Специально для канала @pyway.





