184 строки – это еще с комментариями! И без использования сторонних движков! На самом деле все будет очень просто, в качестве средства отрисовки мы будем использовать любимую ASCII графику в консоли через библиотеку curses. Изображение будет строиться по принципам игры Wolfenstein 3D.
Библиотека curses – это интерфейс к Ncurses, консольной библиотеки для отрисовки всяческих квадратно-текстовых окошек, кнопок и прочих элементов управления в стиле Turbo Pascal или QBasic, кто помнит… Из нее нам понадобится только способность получать размеры терминала и рисовать в нужном месте символ нужного цвета.
Пользователи Windows, к сожалению, в вашей версии Python скорее всего не встроен модуль curses, поэтому вам придется установить пакет. Я использовал такой вариант:
pip install windows-curses
К сожалению, у мне не удалось добиться поддержки цвета на Windows, но я не слишком старался. Это не беда, потому что код был изначально заточен под имитацию оттенков серого через выбор символов разной плотности закраски. На Linux и Macos все должно работать на голом Python и сразу в цвете.
Код, который я вам представлю, является моим портом проекта 3D-Walk, что в свою очередь является портом проекта CommandLineFPS (по ссылке – видео) от javidx9 aka OneLoneCoder. Я внес в код небольшие модификации, исправления и поддержку цвета.
Итак, побежали по коду. Все что, нам надо импортировать:
import curses import locale from math import pi, cos, sin
Затем идут некоторые константы:
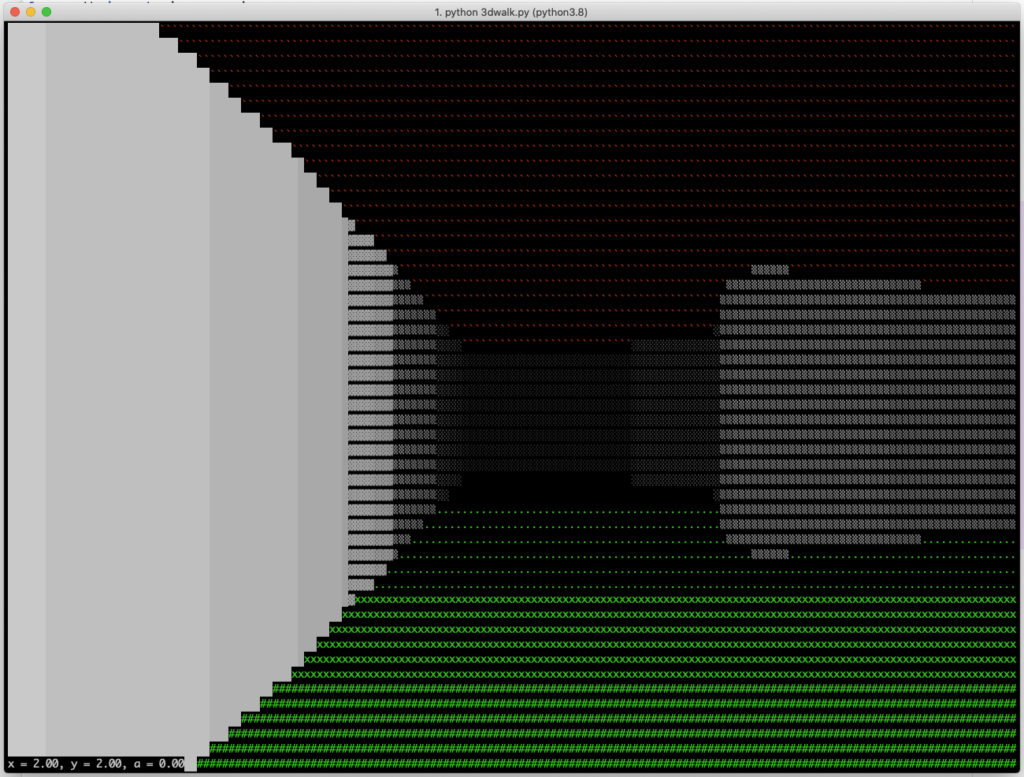
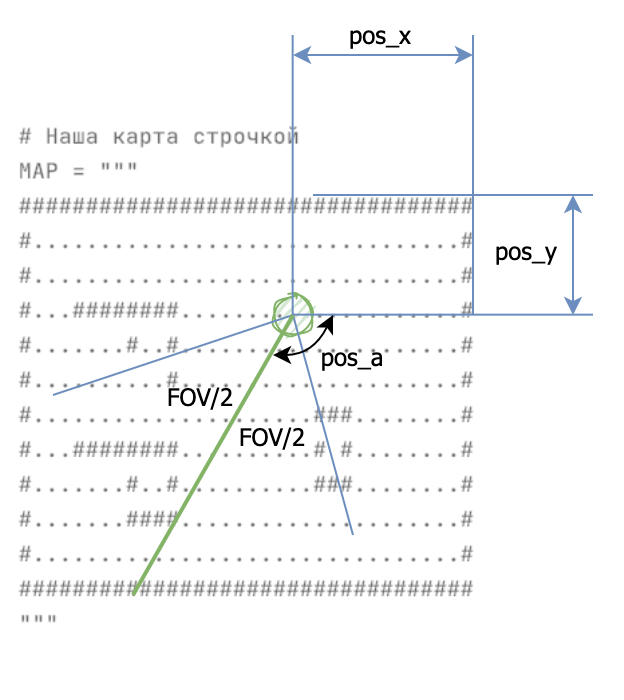
POS_X, POS_Y, POS_A = 2, 2, 0 # Положение и поворот игрока на карте (начальные) ROTATION_SPEED = 0.1 # скорость поворота игрока в радианах SPEED = 0.3 # Скорость игрока вперед назад за одно нажатие FOV = pi / 2 # Ширина угла обзор в радинах RESOLUTION = 0.1 # разрешение шага луча DEPTH = 16 # Максимальная глубина прорисовки # Наша карта строчкой MAP = """ ################ #..............# #..............# #...########...# #.......#..#...# #..........#...# #..............# #...########...# #.......#..#...# #.......####...# #..............# #....##..##....# #...#...#..#...# #....###...#...# #..............# ################ """
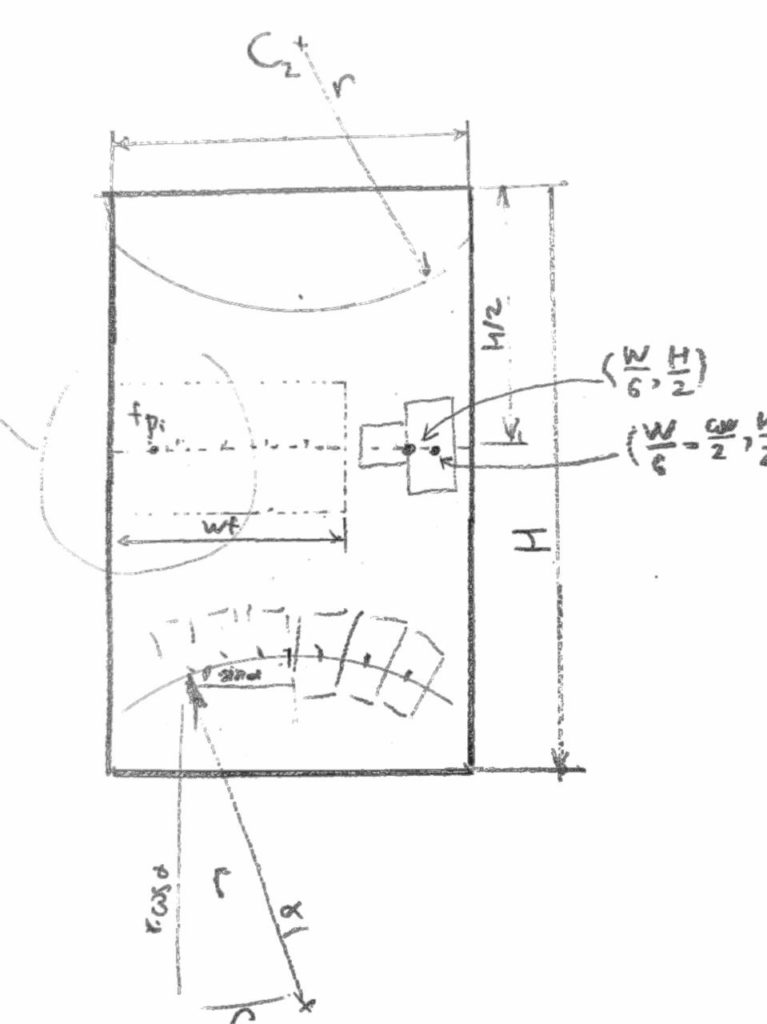
Карта представляет собой двумерную схему лабиринта, вид сверху. Карта записана многострочной строкой, где символом «решетка» обозначены непроходимые стены, а «точками» – пустое пространство. Позиция игрока – число блоков (вероятно, дробное) от угла карты. Угол поворота игрока измеряется в радианах, а широта взгляда по горизонтали FOV – это 90 градусов от левого края экрана до правого. В этим числом будет весело поиграть. Графически выглядит примерно так. Правда, здесь ошибка в точке отсчета, думаю, что внимательный читатель заметит.
Главная функция получает параметром объект экрана (рабочего окна) и запускается через curses.wrapper:
def main_3dwalk(screen): ... curses.wrapper(main_3dwalk)
В начале ее работы мы настраиваем curses:
# для корректного отображение юникода
locale.setlocale(locale.LC_ALL, '')
curses.noecho() # нажатые клавиши не печатаются на экране
curses.curs_set(0) # курсор убран
curses.start_color() # цветной режим
curses.use_default_colors() # стандартная палитра
# инициализация всех цветов!
for i in range(0, curses.COLORS):
curses.init_pair(i, i, -1)
Следующая функция немного преобразует карту MAP, удаляя все переносы строк и считая количество строк и столбцов:
def make_map(string_map):
rows = string_map.strip().split('\n')
h = len(rows)
w = len(rows[0])
return string_map.replace('\n', ''), w, h
# форматируем карту и получаем ее размеры
level_map, map_width, map_height = make_map(MAP)
На выходе будет:
('#################..............##..............##...########...##.......#..#...##..........#...##..............##...########...##.......#..#...##.......####...##..............##....##..##....##...#...#..#...##....###...#...##..............#################', 16, 16)
Это нужно, чтобы функция get_block могла по координатам точки на карте быстро найти в этой строке символ соответствующего блока:
def get_block(x, y):
x, y = int(x), int(y)
if 0 <= x < map_width and 0 <= y < map_height:
return level_map[y * map_width + x]
else:
return '#'
Если координаты попадут по какой-либо причине за пределы карты, что считается, что там всегда глухая стена непроходимого вещества, иными словами – символ '#'. Больше от карты ничего не требуется, только знание, есть ли стена в этой точке пространства или нет!
Далее мы устанавливаем начальную позицию и поворот игрока и запускаем цикл отрисовки кадров и обработки нажатия кнопок.
# текущие положение и угол pos_x, pos_y, pos_a = POS_X, POS_Y, POS_A exit_flag = False # флаг выхода while not exit_flag: # получаем размер экрана в каждом кадре, чтобы не глючить, если юзер изменил размер терминала screen_height, screen_width = screen.getmaxyx() ...
Изображение строится по столбцам. Пока номеру столбца мы находим угол отклонения луча от прямого взгляда. Левая колонка соответствует минимальному углу, то есть pos_a - FOV / 2, а самая правая колонка – pos_a + FOV / 2. Таким образом, вычисляя синус и косинус того угла, мы получаем вектор направления взгляда.
for col in range(screen_width):
# 1. определим направление луча
# угол сканирует от pos_a - FOV / 2 до pos_a + FOV / 2
ray_angle = (pos_a - FOV / 2) + (col / screen_width) * FOV
# вектор, куда смотрит луч на карте
eye_x, eye_y = sin(ray_angle), cos(ray_angle)
Вдоль этого направления испускается луч, стартуя с позиции игрока pos_x, pos_y по направлению eye_x, eye_y. Небольшими шажками (размер шага – константа RESOLUTION), мы продвигаемся вдоль луча и проверяем, пользуясь картой, нет ли в этой точке стены. Как только луч натыкается на стену, в этот момент фиксируется дистанция, цикл прерывается, и алгоритм переходит к следующей колонке. Правильнее было бы называть его не трассировкой лучшей, а чем-то сродни ray casting. Вот код для определения дистанции:
# 2. Ищем ближайшую стену и дистанцию до нее
distance = 0.0
# пока не достигли стены и дистанция менее предельной
while distance < DEPTH:
# луч делает шаг вперед
distance += RESOLUTION
# "текущее" положение на луче
test_x = int(pos_x + eye_x * distance)
test_y = int(pos_y + eye_y * distance)
# смотрим карту, есть ли там стена или край
if get_block(test_x, test_y) == '#':
break # стена. расстояние в distance
Что дает знание расстояния до стены? Многое. Во-первых, чем дальше от нас этот кусочек стены, тем меньше он будет занимать вертикального расстояния. Во-вторых, тем темнее будет его оттенок и слабее заливка.
По вертикали середина стены находится по середине экрана. Если кусочек стены в данной колонке не занимает всю высоту экрана, то все, что ниже него – будет полом, а все что выше – потолком.
ceiling = int(screen_height / 2 - screen_height / distance) # высота потолка floor = int(screen_height - ceiling) # высота пола
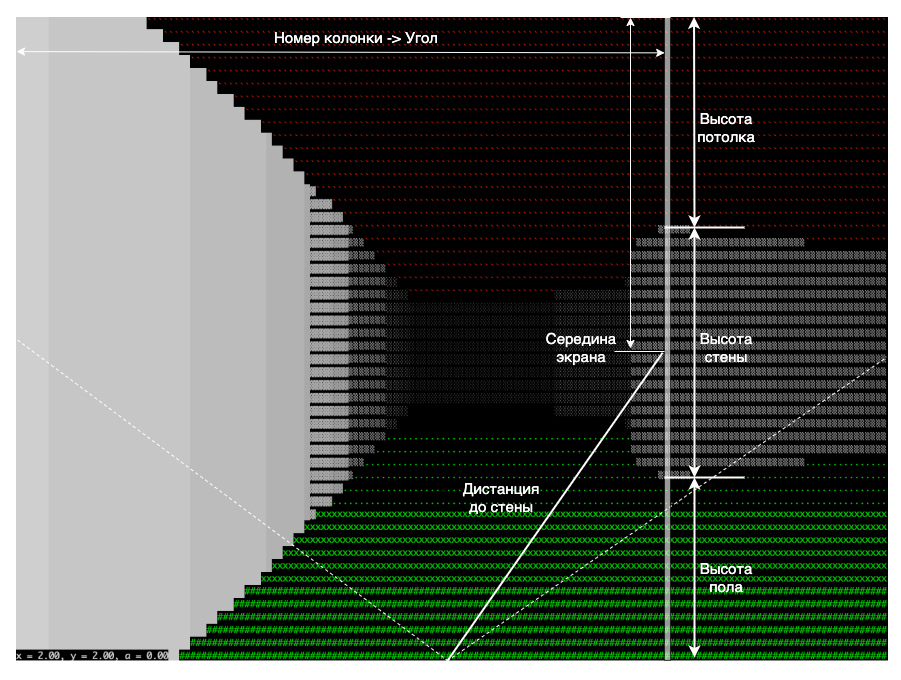
Теперь остается только заполнить колонку сверху вниз. Потолок мы заливаем символом одиночной кавычки красного цвета. А ниже потолка идет серая стена. Цвет и символ заливки стены зависит от дистанции. Сюда прекрасно подойдут квадраты разной плотности, благо они есть в Unicode. Под стеной начинается пол зеленого цвета. Для выразительности символ, который образует пол, тоже зависит от дистанции от нижней кромки экрана, что косвенно отвечает дистанции этого кусочка пола от игровой камеры.
# рисуем вертикальную линию
for row in range(screen_height):
if row <= ceiling: # Ряд выше или равен границе потолка
shade = '`'
color = curses.COLOR_RED
elif floor >= row > ceiling: # Кусок стены
if distance <= DEPTH / 4: # совсем близко
shade = "█"
elif distance <= DEPTH / 3: # ближе
shade = "▓"
elif distance <= DEPTH / 2: # дальше
shade = "▒"
elif distance <= DEPTH: # еще дальше
shade = "░"
else:
shade = " " # совсем далеко
# оттенок цвета, нормированный на предельную дистанцию
color = color_by_distance(1 - (distance / DEPTH))
else:
# Оттенок пола, чем ближе к низу экрана, тем гуще заливка
b = 1 - (row - screen_height / 2) / (screen_height / 2)
if b < 0.25:
shade = '#'
elif b < 0.5:
shade = "x"
elif b < 0.75:
shade = "."
else:
shade = ' '
color = curses.COLOR_GREEN
# заменяем символ в row/col на shade с цветом color
screen.insstr(row, col, shade, curses.color_pair(color))
После циклов остается только отрисовать все изменения на экране:
screen.refresh() # отрисуем все на экране
Дальше мы ожидаем нажатия игроком клавиш управления. Для перемещения используются клавиши WASD, W/S – вперед и назад, A/D – повороты влево и вправо. Esc – выход.
Не забудьте переключиться на английскую раскладку. На русской раскладке игра не будет реагировать!
Преобразовав код клавиши в символ, мы поворачиваем камеру либо смещаем игрока назад или вперед вдоль направления взгляда. Если новое положение игрока оказалось «внутри» стены, то такое движение отменяется. Так просто происходит обработка столкновений со стенами. Вот код, решающий задачу движения игрока:
key_code = screen.getch() # ждем клавишу и обрабатываем
key = chr(key_code) if 0 < key_code < 256 else 0
if key in ('w', 's'):
# шаг вперед или назад
dx, dy = sin(pos_a) * SPEED, cos(pos_a) * SPEED
if key == 's': # назад - обратим вектор
dx, dy = -dx, -dy
# сдвинем игрока в направлении
pos_x += dx
pos_y += dy
if get_block(pos_x, pos_y) == '#': # упс, мы в стене
# отменим движение
pos_x -= dx
pos_y -= dy
elif key == 'a': # поворот налево
pos_a -= ROTATION_SPEED
elif key == 'd': # поворот направо
pos_a += ROTATION_SPEED
elif key_code == 27: # esc
break # выход из игры
В конце не забудем завершить работу curses корректно, восстановив все настройки терминала:
curses.endwin()
Вот и все! Наша бродилка готова! Теперь мы знаем немного больше про 3D графику!
Код программы я залил на gist.github.com. Там два файла: цветная версия для macOS и Linux, и черно-белая для Windows. Наслаждайтесь. Возможно, кто-то из читателей модифицирует этот код, добавив больше цветов, текстур, возможно, противников 🙂
Специально для канала @pyway. Подписывайтесь на мой канал в Телеграм @pyway 👈