Несложно импортировать встроенный модуль или пакет, установленный через pip, или тот, который лежит в директории с нашим кодом (import something). Но что если нужно импортировать код из произвольного места? Конечно, можно было бы скопировать код оттуда в своей проект, но так не рекомендуется делать. Есть и другие решения.
В модуле sys есть переменная path. Она содержит список путей, в которых Python ищет названия модулей для импорта. Пожалуйста, не путайте sys.path и переменную окружения PATH (которая, кстати, доступна через os.environ['PATH']). Это разные вещи, последняя не имеет отношения к поиску модулей Python.
>>> import sys >>> sys.path ['', '/usr/local/Cellar/python@3.8/3.8.1/Frameworks/Python.framework/Versions/3.8/lib/python38.zip', ..., '/usr/local/lib/python3.8/site-packages']
Пустая строка в начале означает текущую рабочую директорию (pwd).
Мы можем влиять на эту переменную, например, добавляя туда свои пути. Если добавить в начало списка, то поиск модулей начнется именно с нового пути.
import sys sys.path.insert(0, '/Users/you/Projects/my_py_lib') import my_module # этот модуль лежит в my_py_lib
Порядок тут важен. Нельзя сделать сначала import, потому что на момент импорта my_module система еще не знает, где его можно найти.
import sys import my_module # ModuleNotFoundError sys.path.insert(0, '/Users/you/Projects/my_py_lib') # поздно
Модуль site
Функция site.addsitedir тоже модифицирует sys.path, добавляя путь в конец списка. Еще она делает некоторые дополнительные вещи, но мы их не касаемся. Пример:
import site
site.addsitedir('/Users/you/Projects/my_py_lib')
import my_module
Также, набрав команду python3 -m site в командной строке, вы можете узнать пути для импорта в текущим интерпретаторе Python.
Минус способов с добавлением путей через sys.path и site – IDE скорее всего не будет видеть и индексировать эти пути, а значит будет много красных подчеркиваний и отсутствие автодополнения, даже если код прекрасно выполняется.
PYTHONPATH
PYTHONPATH – переменная окружения, которую вы можете установить перед запуском интерпретатора. Будучи заданной, она также влияет на sys.path, добавляя пути поиска модулей в начало списка.
На Windows можно использовать команду set. Если надо задать два и более путей, разделите их точкой с запятой:
set PYTHONPATH=C:\pypath1\;C:\pypath2\ python -c "import sys; print(sys.path)" # Пример вывода: ['', 'C:\\pypath1', 'C:\\pypath2', 'C:\\opt\\Python36\\python36.zip', 'C:\\opt\\Python36\\DLLs', 'C:\\opt\\Python36\\lib', 'C:\\opt\\Python36', ..., 'Python36\\lib\\site-packages\\Pythonwin']
На Linux и macOS можно использовать export. Два и более путей разделяются двоеточием:
export PYTHONPATH='/some/extra/path:/foooo' python3 -c "import sys; print(sys.path)" # Пример вывода ['', '/some/extra/path', '/foooo', ...]
Или даже в одну строку:
PYTHONPATH='/some/path' python3 -c "import sys; print(sys.path)"
Кто не знал, ключ -c для python3 просто выполняет строчку кода. И да, лишних пробелов вокруг знака равно не должно быть, это не эстетическая прихоть автора, а такой синтаксис.
PyCharm
Если дополнительные пути заранее известные (не динамические), то в IDE обычно есть возможность задать их из настроек. Покажу на примере PyCharm 2019-2020.
Способ 1
Идем в настройки – Project Interpreter – Нажимаете на выпадающий список сверху – Show All.
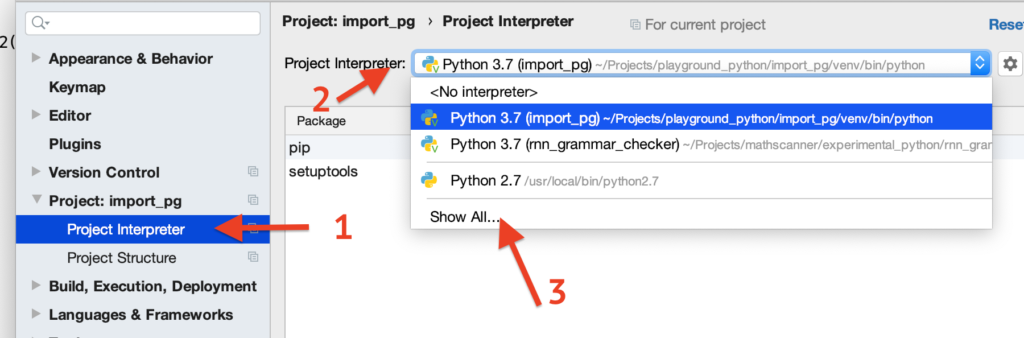
Там находите в списке нужный интерпретатор (тот, что задействован в текущем проекте) и внизу нажимаете иконку с папками.
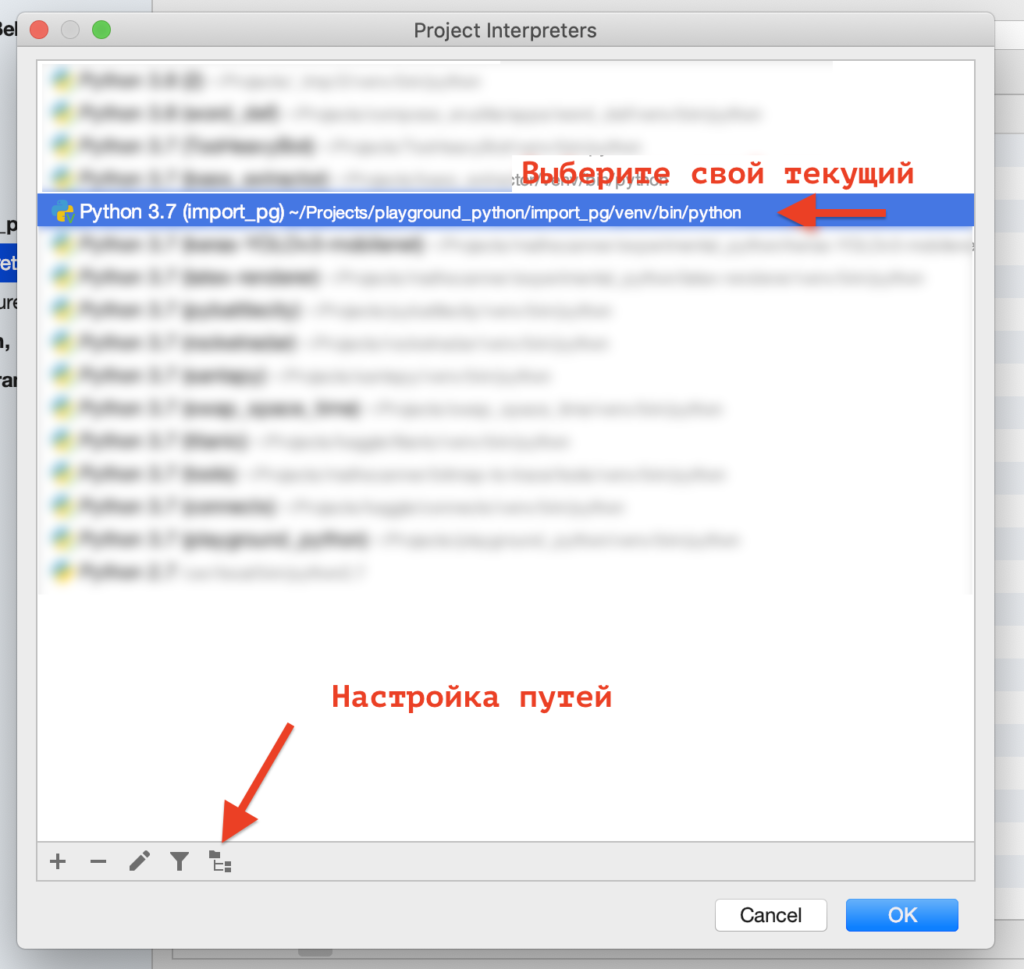
Затем нажимаете на плюсик и добавляете нужные папки, ОК.
Способ 2
Идем в настройки – Project: ваш проект – Project Structure – Add Content Root.
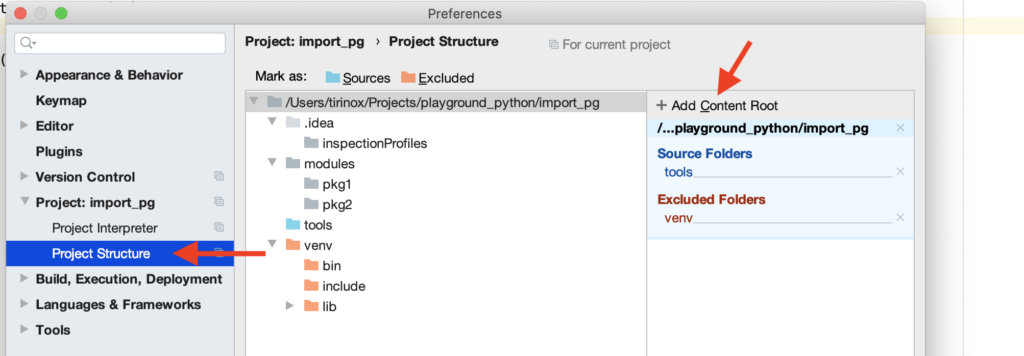
Таким образом, у вас будут работать все фишки IDE для импортированных по сторонним путям модулей, но код будет запускаться корректно только из этой IDE, а чтобы запустить его из-вне, например из терминала, придется все равно задать PYTHONPATH.
Специально для канала @pyway. Подписывайтесь на мой канал в Телеграм @pyway 👈