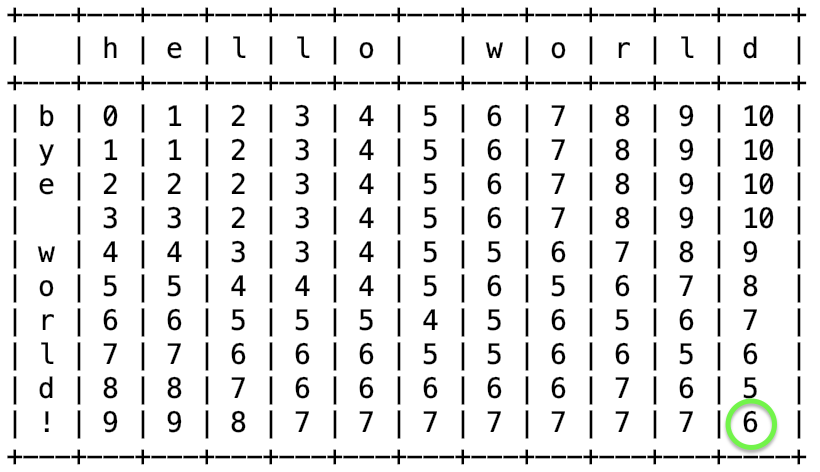
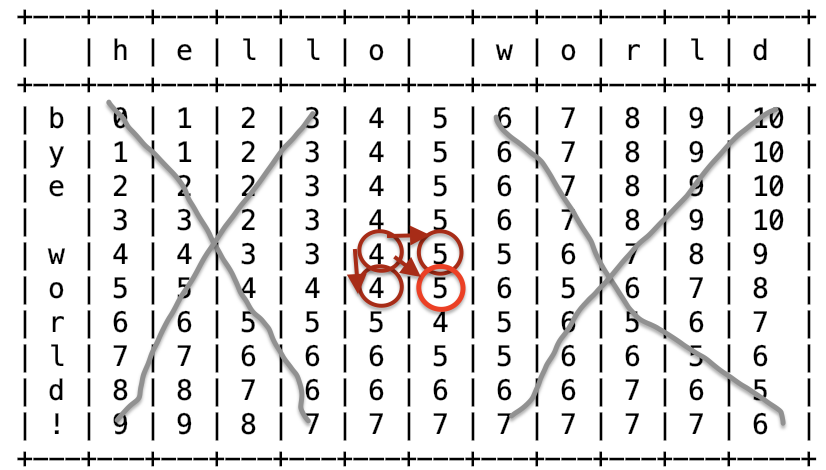
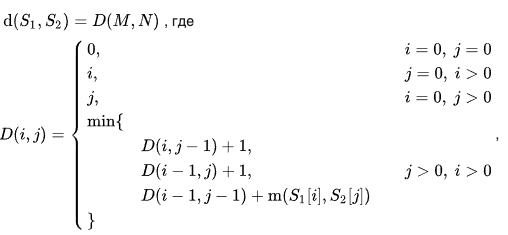Надеюсь, вы уже ознакомились с частью 1.

В этой части мы начнем реализовывать сетевые взаимодействия. Обычно в статьях по сетевому программированию нам предлагают использовать клиент-серверную модель по протоколу TCP. Тут кроется пара неудобств. Во-первых, разделение код на клиентский и серверный. Во-вторых, необходимость клиентам узнавать адрес сервера. В масштабах локальной WiFi сети для небольших игрушек – лишняя трата времени и неудобства. Почему бы нам не позволить клиентам самим находить друг друга? Это не так сложно.
Начнем с того, что у каждой машины в сети есть свой IP адрес из четырех чисел 0-255. В локальной сети обычно (но не всегда) адреса имеют вид 192.168.1.X, где X – разный для разных устройств в сети.
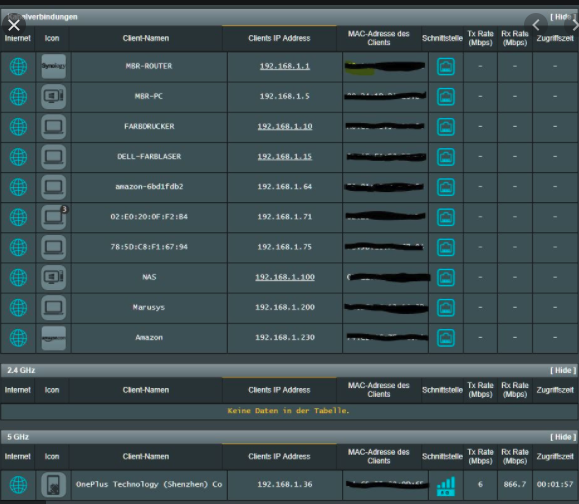
Один из вариантов, который я нашел в сети, предлагал нам просканировать диапазон адресов 192.168.1.1 — 192.168.1.254 и попытаться подключиться к каждому из них. Это вариант меня не устроил, потому что такой брут-форс выполняется долго, да и вообще метод топорный. В моем методе не придется узнавать даже свой IP.
Будем работать по протоколу UPD, обмениваясь датаграммами (короткими сообщениями). Это простой протокол. UDP отличается от TCP тем, что не требует устанавливать соединение, однако в UDP нет гарантий доставки сообщений (получатель не отправляет отправителю подтверждение получения данных), как следствие не гарантирован порядок получения сообщений.

Отправитель просто отправляет данные в сеть либо конкретной машине или на всю подсеть (broadcast), и будь, что будет. Кто-то может принять эти данные, либо они вообще могут потеряться. Чтобы различать разные прикладные приложения, используют номер порта (число до 65535). Потенциальный получатель просто начинает слушать свой порт, вдруг кто-то на него отправит данные.
Казалось бы, протокол UDP ненадежен, однако, UPD работает быстрее, чем TCP, так как не тратится время на подтверждения при обмене. UPD подходит неплохо для игр, стримминга, телефонии и тому подобного. А еще он отлично подойдет для наших целей обнаружения.
Я знаю отличную шутку про UDP, но боюсь, она до вас не дойдет!
С просторов Интернета…
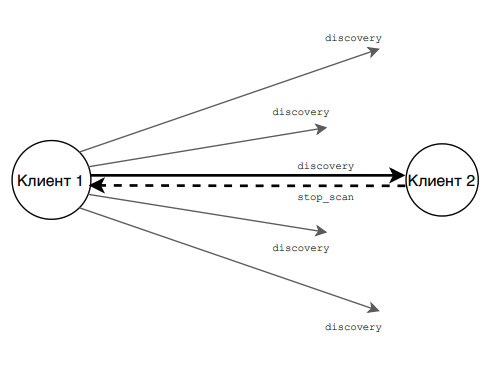
Как только клиент игры запустится, он начнет переодически отправлять широковещательные UDP пакеты в сеть (с пометкой discovery), авось кто услышит. Но и сам начинает сразу после отправки слушать, не пришел ли ему ответ (5 секунд). Затем снова оправляет запрос.
В тоже время какой-то другой клиент сети, который уже ищет соперника, получает от него выше-указанное сообщение discovery и отвечает просьбой прекратить сканирование (stop_scan), после чего останавливает сканирование сети. Клиент получивший stop_scan проверяет, его ли идентификатор в нем указан. Если да, то он также останавливает сканирование.
Оба клиента теперь знают адреса друг друга и готовы начать обмениваться пакетами напрямую между собой уже в рамках игровой сессии. Задача обнаружения выполнена.
Класс сети
Начнем писать код с класса сети Networking (по ссылке полный код класса). Он абстрагирует создание и настройку UDP сокета, обмен данными через него (кодирование и декодирование данных в JSON).
Импортирует стандартный модуль socket. Создание сокета:
import socket
...
class Networking:
...
@classmethod
def get_socket(cls, broadcast=False, timeout=TIME_OUT):
sock = socket.socket(socket.AF_INET, socket.SOCK_DGRAM, socket.IPPROTO_UDP)
# чтобы на одной машине можно было слушать тотже порт
sock.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEPORT, 1)
if broadcast:
sock.setsockopt(socket.SOL_SOCKET, socket.SO_BROADCAST, 1)
sock.settimeout(timeout)
return sock
Отправку данных совершить очень просто. Кодируем данные в JSON, потом в байты, потом посылаем через сокет на указанный адрес и порт:
def send_json(self, j, to):
data = bytes(json.dumps(j), 'utf-8')
return self._socket.sendto(data, (to, self.port_no))
Широковещательная отправка отличается только тем, что получатель будет to="<broadcast>":
def send_json_broadcast(self, j):
return self.send_json(j, "<broadcast>")
С прием все несколько хитрее. Сначала надо сделать bind (привязаться к порту для получения на него сообщений). Теперь сетевой стэк будет знать, что именно наша программа должна получать данные, пришедшие на компьютер именно на этот порт.
def bind(self, to=""):
"""
Привязаться к порту, то есть начать слушать с него сообщения
После bind можно вызывать recv_json
:param to: интерфейс ("" - любой)
"""
self._socket.bind((to, self.port_no))
Затем мы вызываем на сокете recvfrom. Если есть данные, то декодируем JSON, а если не дождались (у меня стоит тайм-аут 1 секунду), то возвращаем None.
def recv_json(self):
try:
# получить датаграмму и адрес из сокета
data, addr = self._socket.recvfrom(self.BUFFER_SIZE)
# декодируем в юникод и загружаем из JSON
return json.loads(data.decode('utf-8', errors='ignore'), encoding='utf-8'), addr
except json.JSONDecodeError:
logging.error(f'JSONDecodeError!')
except socket.timeout:
pass # ничего не пришло
return None, None
Учтите! На наш сокет могут приходить также сообщения от чужих программ или от наших же клиентов игры, но в другом состоянии. А еще broadcast пакеты приходят также и обратно себе на клиент. Их надо фильтровать. Поэтому добавим метод, который несколько раз в течение определенного времени (5 секунд, допустим) будет получать из сокета данные и передавать их на проверку внешней функции predicate, которая вернет False, если это чужие данные и True, если данные подходят для текущего состояния игры. Сам метод recv_json_until вернет данные и адрес, с которого они пришли.
def recv_json_until(self, predicate, timeout):
t0 = time.monotonic()
while time.monotonic() < t0 + timeout:
data, addr = self.recv_json()
if predicate(data):
return data, addr
return None, None
Discovery Protocol
Мы готовы реализовать протокол по обнаружению других клиентов, ждущих начала игры.
import random
import network
import logging
class DiscoveryProtocol:
A_DISCOVERY = 'discovery'
A_STOP_SCAN = 'stop_scan'
def __init__(self, pid, port_no):
assert pid
self._my_pid = pid
self._network = network.Networking(port_no, broadcast=True)
self._network.bind()
Здесь pid (player ID) – уникальный идентификатор, чтобы отличаться от других игроков. Он создается случайно при запуске игры pid = random.getrandbits(64). Я не стал использовать IP адрес, потому что на одной машине может быть несколько запущенных клиентов (например, во время отладки). Думаю, большинство читателей первый раз будут пробовать запускать два клиента на одной машине, а не на разных.
Также мы создаем в конструкторе класс Networking, настраиваем его на широковещательную отправку и говорим ему также слушать порт.
Формат отправки сообщений будет в виде словаря с ключом action (тип действия). Например:
{
"action": "discovery",
"sender": 1234
}
Метод для посылки таких сообщений:
def _send_action(self, action, data=None):
data = data or {}
self._network.send_json_broadcast({'action': action, 'sender': self._my_pid, **data})
Сам процесс сканирования: в бесконечном цикле рассылаем сообщение discovery, и сразу переходим в режим приема. 5 секунд ждем подходящее сообщение от других клиентов. Если оно пришло, то обрабатываем событие и прекращаем сканирование, выходя из цикла. При этом на сообщение discovery мы обязаны ответить stop_scan, чтобы удаленные клиент понял, что он нас нашел и тоже вышел из процесса сканирования.
def run(self):
while True:
logging.info('Scanning...')
# рассылаем всем сообщение A_DISCOVERY
self._send_action(self.A_DISCOVERY)
# ждем приемлемого ответа не более 5 секунд, игнорируя таймауты и неревалентные пакеты
data, addr = self._network.recv_json_until(self._is_message_for_me, timeout=5.0)
# если пришло что-то наше
if data:
action, sender = data['action'], data['sender']
# кто-то нам отправил A_DISCOVERY
if action == self.A_DISCOVERY:
# отсылаем ему сообщение остановить сканирование A_STOP_SCAN, указав его PID
self._send_action(self.A_STOP_SCAN, {'to_pid': sender})
elif action == self.A_STOP_SCAN:
# если получили сообщение остановить сканирование, нужно выяснить нам ли оно предназначено
if data['to_pid'] != self._my_pid:
continue # это не нам; игнорировать!
return addr, sender
Как понять, что сообщение нужное? В словаре должен быть ключ "action", который принимает значения «discovery» или «stop_scan«, а еще требуем, чтобы pid отправителя был не наш (фильтруем свои же сообщения). Остальные сообщения игнорируются.
def _is_message_for_me(self, d):
return d and d.get('action') in [self.A_DISCOVERY, self.A_STOP_SCAN] and d.get('sender') != self._my_pid
Код для тестирования алгоритма обнаружения:
if __name__ == '__main__':
print('Testing the discovery protocol.')
pid = random.getrandbits(64)
print('pid =', pid)
info = DiscoveryProtocol(pid, 37020).run()
print("success: ", info)
Полный код класса здесь discovery_protocol.py.
Запустите один клиент. Он будет висеть в состоянии сканирования сети. А теперь запустите второй клиент. Они сразу найдут друг друга:
Testing the discovery protocol.
pid = 8100514396826939414
success: (('192.168.1.99', 37020), 5614644081426404292)
Примечание. Этот метод обнаружения будет работать, вероятно, только в пределах вашей локальной сети (одного роутера), потому что любой адекватный роутер на стороне провайдера будет резать широковещательные пакеты. Представляете, какой бы спам начался, если бы была возможность рассылать пакеты сразу всем устройствам, подключенным к Интернет в мире?
На этом все! В следующей части мы реализуем сам сетевой геймплей между клиентами, которые нашли друг друга по этому протоколу.
Специально для канала @pyway. Подписывайтесь на мой канал в Телеграм @pyway 👈