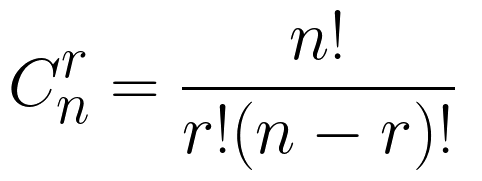Погорим о наследовании. Если один класс унаследован от другого, то он от него перенимает себе методы и атрибуты своего родителя. Вы, конечно, можете переопределить некоторые из них или добавить свою новую функциональность – в этом и есть смысл наследования. Но те методы, которые вы не переопределяли, так и останутся родительскими. Таким образом, когда вы вызываете метод экземпляра класса, Python должен посмотреть, есть ли в нем этот метод. Если есть – он и будет вызван, а если его нет, то ему придется проверить классы-родители данного класса. Вдруг, у них есть?
class Parent:
def earn_money(self):
print('Родитель зарабатывает')
class Child(Parent):
def play(self):
print('Ребенок играет')
c = Child()
c.play() # Ребенок играет
c.earn_money() # Родитель зарабатывает
В коде выше ребенок играет, играть – это ему присущий метод. Но зарабатывать деньги он пока не умеет, но его родитель вполне может с этим справиться. Поэтому метод earn_money будет взят от родителя. Думаю, тут все ясно.
Сложнее ситуация становится, когда иерархия классов разрастается. Не будем забывать, что Python поддерживает множественное наследование, что сделает граф отношений между классами весьма запутанным. Методы с одинаковыми именами могут быть определены в любых классах из всей иерархии. И если ответ на вопрос «где искать?» довольно прост: сначала посмотри в самом классе, а потом в его родителях; то ответ на вопрос «в каком порядке искать?» не такой тривиальный. Например, взгляните на такую иерархия классов:
class O: ... class A(O): ... class B(O): ... class C(O): ... class D(O): ... class E(O): ... class K1(A, B, C): ... class K2(B, D): ... class K3(C, D, E): ... class Z(K1, K2, K3): ...
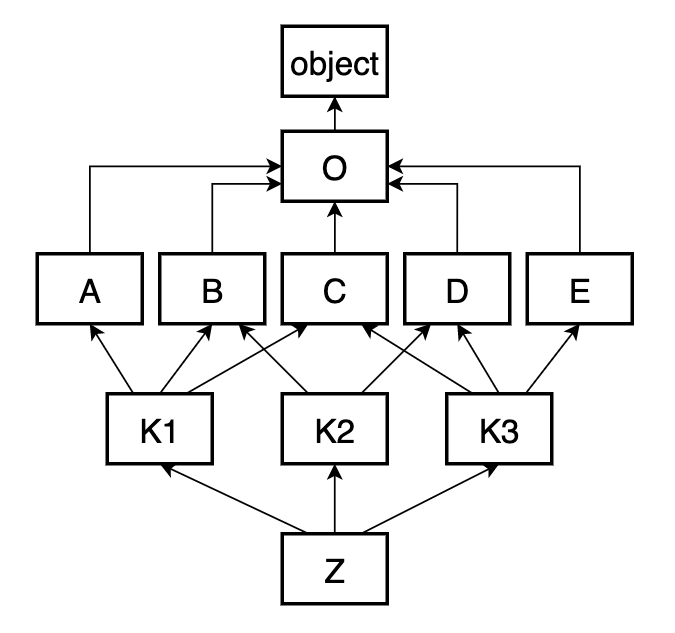
Сможет сходу назвать порядок поиска методов в этой иерархии? Я вот ошибся с первой попытки, и даже со второй. Узнаем правду методом mro():
print(Z.mro())
# [<class '__main__.Z'>, <class '__main__.K1'>, <class '__main__.A'>, <class '__main__.K2'>, <class '__main__.B'>, <class '__main__.K3'>, <class '__main__.C'>, <class '__main__.D'>, <class '__main__.E'>, <class '__main__.O'>, <class 'object'>]
# сделаем понагляднее вывод, печатая только имена классов со стрелочками:
def print_mro(T):
print(*[c.__name__ for c in T.mro()], sep=' -> ')
print_mro(Z)
# Z -> K1 -> A -> K2 -> B -> K3 -> C -> D -> E -> O -> object
Что же такое этот MRO?
Аббревиатура MRO – method resolution order. А по-русски это переводится как «порядок разрешения методов». Но! Тоже самое относится не только к методам, но и к прочим атрибутам класса, так как методы – это частный случай более общего понятия «атрибут».
Метод класса Z.mro() возвращает нам список классов ровно в том порядке, в котором Python будет искать методы в иерархии классов пока не найдет нужный или не выдаст ошибку.
Конечный класс в цепочке всегда – object; от него неявно наследуются все объекты в Python 3. Поэтому любое множественное наследование (когда у класса более одного непосредственного родителя) порождает ромбовидные структуры, потому что все цепочки в конечном счете сходятся в object.
Для простого ромбовидного наследования MRO будет следующим: C -> A -> B -> object. Сначала методы ищутся в C, потом в A и B (потому что class C(A, B):), в конце, естественно object.
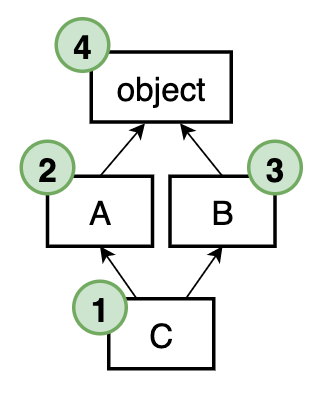
В более сложных иерархиях потребуется специальный алгоритм.
Алгоритм C3-линеаризации
Какие критерии должны быть для алгоритма разрешения методов?
- Каждый класс должен входить в список ровно 1 раз.
- Если какой-то класс D наследуется от нескольких классов, допустим, A, B, C (
class D(A, B, C):), в таком же порядке они должны появиться в MRO.D -> ... -> A -> ... -> B -> ... -> C -> ...Между ними могут оказаться и другие классы, но исходный порядок должен быть соблюден. - Родители данного класса должны появляться по порядку старшинства. Сначала идут непосредственные родители, потом дедушки и бабушки, но не наоборот.
Алгоритм, который удовлетворяет этим условиям был предложен в 1996 года и называется C3 superclass linearization. Линеаризация в данном случае – это процесс превращения графа наследования в плоский список. А С3 он называется из-за наличия трех основных свойств. Важнейшее свойство здесь – это монотонность – это свойство, которое требует соблюдения в линеаризации класса-потомка того же порядка следования классов-прародителей, что и в линеаризации класса-родителя.
В Python данный алгоритм появился еще в далекой версии 2.3.
Если вы обладаете навыками чтения английской технической литературы, то можете ознакомиться с оригиналом статьи, PDF я нашел на просторах интернета. Есть и замечательное описание алгоритма на русском языке в статье на Хабре. Там же есть и примеры составления линеаризаций.
Почему именно так?
Вернемся к исходному примеру.
class O: ... class A(O): ... class B(O): ... class C(O): ... class D(O): ... class E(O): ... class K1(A, B, C): ... class K2(B, D): ... class K3(C, D, E): ... class Z(K1, K2, K3): ...
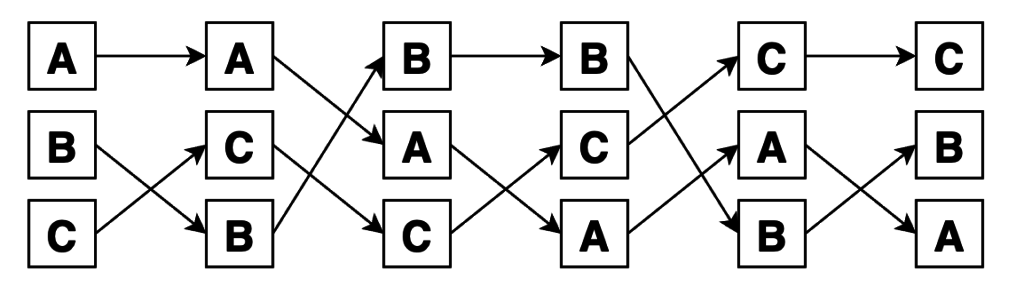
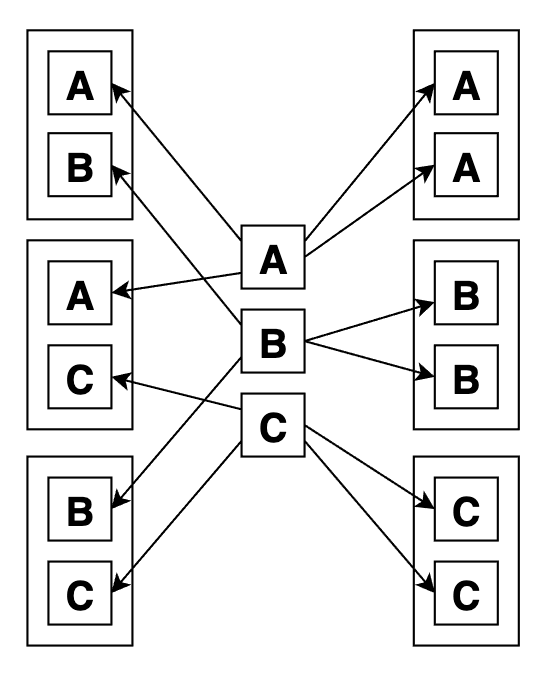
Почему Z -> K1 -> A -> K2 -> B -> K3 -> C -> D -> E -> O -> object, а не, например, Z -> K1 -> K2 -> K3 -> A -> B -> C -> D -> E -> O -> object? На самом деле обе из них имею место быть, но по реализации алгоритма получается именно первый вариант. Графически MRO на диаграмме выглядит так:
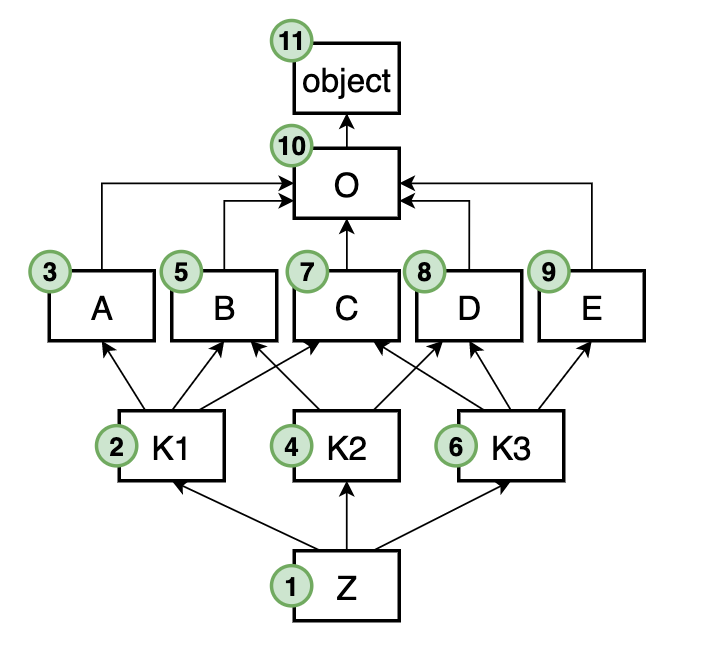
Попробуем обосновать такой порядок. C начала, конечно же, положим в MRO-список оконечный класс Z. Потом класс K1, так как он идет первым в списке наследования Z. Далее, видим, что идет класс A. Этот класс больше никому не является родителем, кроме как K1, следовательно алгоритм добавляет A сразу после K1, не нарушив никаких правил. После A непосредственно не может идти класс B, так как за ним пришлось бы где-то еще воткнуть K2, и получилось бы так, что K2 будет позже B, что запрещено. Нет! Ставим тогда сначала K2, потом только B. Далее, по схожей причине нужно поставить K3, дабы он не оказался после своего родителя C. Дополняем список классами D и E в их порядке. И остается только завершить список классами O, который общий родитель для всех прочих классов, и object, который родитель для O. Как видите никакой родитель не стоит перед стоим потомком (но может стоять перед чужим). А также порядок следования классов в MRO согласован с порядком наследования.
Вариант реализации алгоритма и его работу на этом примере я разместил здесь (можно запустить и поиграться прямо браузере. Автор реализации – не я. Нашел на Github.
Когда нельзя линеаризовать?
Думаю, такой вопрос имеет место быть на собеседовании. Вас могут попросить привести пример иерархии классов, не поддающихся линеризации по стандартному алгоритму. Вот первый неразрешимый пример:
class X: ... class Y: ... class A(X, Y): ... class B(Y, X): ... class G(A, B): ...
Для A порядок X -> Y, а для B – обратный Y -> X. Класс G обязан удовлетворить обоим порядкам наследования, что невозможно, так как они противоречат друг другу. Возникнет ошибка в строке объявления класса G:
class G(A, B): ... TypeError: Cannot create a consistent method resolution order (MRO) for bases X, Y
Или вот второй пример:
class X: ... class Y(X): ... class A(X, Y): ...
Здесь класс X наследуется дважды, и куда мы его не поместили в цепочке MRO, он либо нарушит правило старшинства (A -> X -> Y -> object), либо порядка наследования (A -> Y -> X -> object).
Как задать свой порядок MRO?
Это возможно, используя метаклассы. Для «конфликтного» класса мы определим особый метакласс, который переопределяет явно метод mro(), указывая вручную, какой именно должен быть порядок разрешения методов. На первом «неразрешимом» примере решение будет такое:
class X: ...
class Y: ...
class A(X, Y): ...
class B(Y, X): ...
class MyMRO(type): # наследование type = это метакласс
def mro(cls):
return (cls, A, B, X, Y, object) # явно задаем порядок!
class G(A, B, metaclass=MyMRO):
...
print_mro(G) # G -> A -> B -> X -> Y -> object
# никаких ошибок!
Ты super()!
Иногда требуется обратиться к родительскому классу из дочернего. Например, если дочерний класс переопределяет метод инициализации, то ему, как правило, следует вызвать инициализатор родительского класса. Делать по имени класса не очень удобно и порождает кучу проблем и багов, особенно, если наследование множественное, и мы мало что знаем об устройстве и родственных связях наследуемых классов. Тем более если со временем иерархия измениться, нужно будет поддерживать все вызовы в актуальном состоянии. Поэтому плохо писать так:
class C(A, B):
def __init__(self):
A.__init__(self)
B.__init__(self)
Гораздо удобнее обратиться к следующему в цепочка MRO классу-родителю через super().
super() – это особенный прокси-класс к нужному родительскому классу. Вот так правильно можно обратиться к родительскому классу:
class C(B, A):
def __init__(self):
super().__init__()
В родительских классах тоже используется super(), поэтому все инициализаторы сработают в порядке MRO.
Специально для канала @pyway. Подписывайтесь на мой канал в Телеграм @pyway 👈