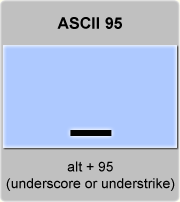
Знак подчеркивания _ или underscore занимает особое место в Python.
Подчеркивание имеет множество применений, как эстетических конвенций (необязательная договоренность разработчиков оформлять код с подчеркиваниями), так и функциональных, т. е. реально затрагивающих исполнение кода (такие места буду отмечать знаком ⚠️).
- змеиный_регистр (snake_case)
- имена магических методов и переменных
- «приватные» члены класса и коверкание имен (mangling)
- игнорирование значения переменной
- разделение разрядов в числах
- избегание конфликтов с ключевыми словами
- хранение последнего результата в интерпретаторе
Поехали от самого известного к необычному!
Змеиный регистр
Это конвенция именования переменных и функций в Python: название начинается с маленькой буквы, а слова разделяют знаком подчеркивания. Думаю все и так знают:
foo_bar = 10
def my_function_to_do_something_special(arg_1, arg_2):
...
# не принято писать так:
FooBar = 10
carSpeed = 60
Dont_Do_Like_This()
Магические имена
Опять же, думаю, все видели, что имена магических методов и магических переменных начинаются и заканчиваются в двух знаком подчеркивания (__init__). Вот, например, так:
class CrazyNumber:
__slots__ = ('n',)
def __init__(self, n):
self.n = n
def __add__(self, other):
return self.n - other
def __sub__(self, other):
return self.n + other
def __str__(self):
return str(self.n)
Конфликт с ключевым словом
Если вам очень нужно назвать переменную, функцию или аргумент также как и какое-либо ключевое слово из Python, то принято в конце ставить знак подчеркивания, дабы избежать конфликта.
Бывает актуально, если вы пишите какой-то биндинг к сторонней библиотеке, где, к несчастью, некоторые понятия имеют такое же имя как и ключевые слова:
Tkinter.Toplevel(master, class_='ClassName')
Но! Если вы пишите классовый метод, принято первый аргумент называть cls, а не class_.
Приватные члены
Приватные члены – это такие, которые предполагаются только для внутреннего использования классом или модулем. Они не должны использоваться из-вне, хотя Python и не запрещает это делать. Есть способы получить доступ к любым приватным вещам, если очень нужно.
Разделение на приватные и публичные члены – это механизм сокрытия (пожалуйста, не путайте с инкапсуляцией). Я писал про разницу между ними в статье «Сокрытие в Python». Здесь кратко напомню.
Если имя начинается с одного подчеркивания, то такая переменная, метод или класс в модуле считается приватной. Если вы обратитесь к приватной вещи из-вне модуля или класса, где она определена, то, вероятно, ваша IDE просто подчеркнет такой код, как подозрительный, но он будет выполняться без ошибок или предупреждения.
# приватные переменные в модуле
_internal_variable = 'some secret'
_my_version = '1.6'
# приватная функция модуля
def _private_func():
...
# приватный класс модуля
class _Base:
# приватная переменная класса
_hidden_multiplier = 1.2
def __init__(price):
# приватное поле экземпляра класса
self._price = price * self._hidden_multiplier
⚠️ Влияние на поведение: from module import * не будет импортировать приватные члены модуля. Но можно импортировать их принудительно: from module import _Base, _my_version
Еще приватнее или name mangling
⚠️ Если мы будем использовать не одно, а целых два подчеркивания перед именем, то это задействует механизм name mangling. На русский это можно перевести как «коверкание имени». Python исковеркает данное имя, чтобы избежать конфликтов имен атрибутов между классами в иерархии наследования. Естественно, внутри класса, где определен атрибут с двойным подчеркиванием спереди, он будет доступен также по своему имени. Но на самом деле к имени добавится префикс _ClassName. Проиллюстрирую правило манглинга на примере. Допустим есть класс Tree, и вы пишите метод __rebalance, то его имя превратится в _Tree__rebalance при доступе из-вне класса. Пример кода:
class Tree:
def __rebalance(self):
print('Tree.__rebalance')
def public_method(self):
# метод доступен по своему имени
self.__rebalance()
class BinaryTree(Tree):
# этот метод не перекроет __rebalance из Tree!
def __rebalance(self):
print('BinaryTree.__rebalance')
tree = Tree()
tree._Tree__rebalance() # Tree.__rebalance
btree = BinaryTree()
btree._Tree__rebalance() # Tree.__rebalance
btree._BinaryTree__rebalance() # BinaryTree.__rebalance
Кстати, на слэнге двойное подчеркивание называется dunder. Добавление третьего и четвертого подчеркиваний к дополнительным эффектам не приведет!
Игнорирование
Если вам не нужно значение переменной, назовите его просто подчеркиванием.
# просто повтор 10 раз, а счетчик не нужен
for _ in range(10):
print('Hello')
Так же при распаковке коллекций в переменные вы можете применить сколько угодно подчеркиваний.
def tup():
return 1, 2, 3, 4
# третье не нужно
a, b, _, d = tup()
print(a, b, d) # 1 2 4
# второе и четвертое не нужны
a, _, c, _ = tup()
print(a, c) # 1 3
# только первое
a, *_ = tup()
print(a) # 1
# первое и последние
a, *_, d = tup()
print(a, d) # 1 4
# нужны только 2 последних
*_, c, d = tup()
print(c, d) # 3 4
Примечание: использовать значение _ в принципе можно (в нем будет последний присвоенный результат), но зачем?
С аргументами функций немного иначе. Среду аргументов может быть только одно подчеркивание. Если нужно игнорировать два и более аргумента, то перед их именами ставим подчеркивание, тогда IDE не будет ругаться.
# нужен только x
def get_only_x(x, _y, _z):
return x
# так нельзя!
def get_only_x(x, _, _):
return x
Разделение разрядов в числах
Фишка добавлена в Python 3.6. Можно разделять разряды в длинных числах для облегчения чтения кода.
>>> 1_000_000 1000000 >>> 0b1011_1100_0000_1111 48143 >>> 0x_ee12_3b5f 3994172255 >>> 0o_1_2_3_4_5_6_7 # можно хоть каждый разряд отделить! 342391 >>> 10_20_30_40 10203040
Последний результат в интерпретаторе
⚠️ Лично я не знал, про эту фишку, пока не стал писать эту статью. А между тем, она супер удобна, если вы используете интерпретатор Python как калькулятор:
>>> 10 + 20
30
>>> _ + 3
33
>>> _ * 3 + _ * 2
165
# print возвращает None, но None не затирает _ !
>>> print('hello')
hello
>>> None
>>> _
165
Может, я что-то упустил? Если да, присылайте мне в Телеграм!
😈 Специально для канала @pyway. Подписывайтесь на мой канал в Телеграм @pyway 👈