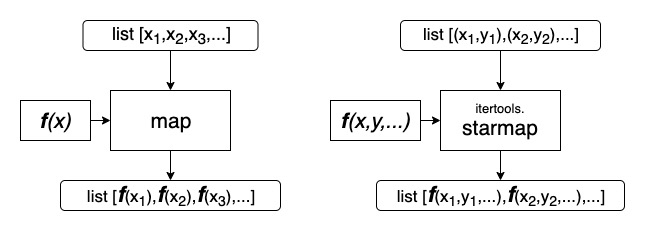
Мы говорили про map и itertools.starmap, но я тут подумал… Зачем они, если есть замечательные генераторные выражения:
- Они умеют делать: генераторы, списки list, словари dict и множества set.
- Поддерживают вложенные циклы для обработки многомерных данных
- Умеют фильтровать данные, как filter
- Обладают лаконичным и понятным синтаксисом
По-английски они называются в зависимости от типа данных на выходе: generator expressions и list/dictionary/set comprehensions.
Если нам нужен генератор, то ставим круглые скобки. Если нужен сразу список – квадратные. Если нужен словарь или множество – фигурные. А внутри цикл for/in. Наш «прибавлятор» единицы стал короче и без лямбд:
>>> list(map(lambda x: x + 1, [1, 2, 3, 4])) [2, 3, 4, 5] >>> [x + 1 for x in [1, 2, 3, 4]] [2, 3, 4, 5]
Пример на замену starmap не то чтобы сильно короче, но значительно понятнее, потому что виден фактический вызов pow и разумные имена переменных:
>>> from itertools import starmap >>> list(starmap(pow, [(2, 4), (3, 2), (5, 2)])) [16, 9, 25] >>> [pow(base, exp) for base, exp in [(2, 4), (3, 2), (5, 2)]] [16, 9, 25]
Если нужно множество (коллекция без повторов), то все то же самое, но скобки фигурные. Пример: все уникальные буквы слова:
>>> {r for r in 'BANANA'}
{'N', 'B', 'A'}
Если нужен словарь, то скобки также фигурные, но генерируем парами «ключ: значение». Пример: ключ – строка, значение – строка задом наперед:
>>> {key: key[::-1] for key in ["Mama", "Papa"]}
{'Mama': 'amaM', 'Papa': 'apaP'}
Наконец, если нужен генератор, то скобки круглые. Генератор вычисляет и выдает значения лениво (по одному, когда они требуются):
>>> g = (x ** 2 for x in [1, 2, 3, 4]) >>> next(g) 1 >>> print(*g) 4 9 16
Если функция принимает ровно 1 аргумент, то передавая в нее генератор можно опустить лишние круглые скобки:
>>> sum(x ** 2 for x in [1, 2, 3, 4]) 30
Специально для канала @pyway. Подписывайтесь на мой канал в Телеграм @pyway 👈