Есть мнение, что каждый программист должен написать в жизни хотя бы один язык программирования, либо реализовать уже существующий, но своими руками. В качестве примера мы начнем с самого простого и создадим Brainfuck. Согласно Вики:
Brainfuck — один из известнейших эзотерических языков программирования, придуман Урбаном Мюллером (нем.Urban Müller) в 1993 году, известен своим минимализмом. Название языка можно перевести на русский как вынос мозга, оно напрямую образовано от английского выражения brainfuck (brain — мозг, fuck — иметь половое сношение), т. е. заниматься ерундой. Язык имеет восемь команд, каждая из которых записывается одним символом. Исходный код программы на Brainfuck представляет собой последовательность этих символов без какого-либо дополнительного синтаксиса.
Википедия.
Описание 8 команд:
| Команда Brainfuck | Описание команды |
|---|---|
| Начало программы | выделяется память под 30 000 ячеек с нулевыми начальными значениями |
> | перейти к следующей ячейке |
< | перейти к предыдущей ячейке |
+ | увеличить значение в текущей ячейке на 1 |
- | уменьшить значение в текущей ячейке на 1 |
. | напечатать значение из текущей ячейки |
, | ввести извне значение и сохранить в текущей ячейке |
[ | если значение текущей ячейки ноль, перейти вперёд по тексту программы на ячейку, следующую за соответствующей ] (с учётом вложенности) |
] | если значение текущей ячейки не нуль, перейти назад по тексту программы на символ [ (с учётом вложенности) |
Реализация интерпретатора на Python
Интерпретатор читает программу и выполняет ее сразу на лету.
Первым делом надо прочитать целиком файл с исходником на BF, имя которого мы передаем первым параметром командной строки:
if __name__ == '__main__':
if len(sys.argv) == 2:
# один аргумент - имя файла, который надо выполнить
with open(sys.argv[1], 'r') as f:
code = f.read()
run(code) # запустить код
else:
print(f'usage: python {sys.argv[0]} file.bf')
После того, как код прочитан, мы создаем память из 30 000 ячеек, заполненными нулями. Устанавливаем счетчик команд и указатель на ленте ячеек на 0. Инициализация имеет такой вид:
mem_size = 30000 memory = [0] * mem_size # оперативная память программы data_ptr = 0 # индекс текущей ячейки памяти (memory) instr_ptr = 0 # индекс текущей инструкции кода (code)
Далее в цикле читаем ячейку, если это одна из наших 8 команд, то выполняем, иначе пропускаем (это могут быть пробелы и переносы строк, их просто игнорируем). После выполнения команды, указатель сдвигается вправо по коду (увеличивается на единицу). Программа выполняется до тех пор, пока счетчик инструкций не выйдет за пределы размера кода.
С командами типа «+», «-«, «<«, «>» проблем в понимании быть не должно, они делают простые действия. Разве что, вам следует обратить внимание на то, что я зацикливаю оперативную память, если команда смещения переходит границу (команда < от 0 сдвинет на 29999 ячейку, а команда > с ячейки номер 29999 сдвигает на 0 ячейку).
Фрагмент цикла:
# выполняем - пока не вылетели за пределы кода
while instr_ptr < len(code):
command = code[instr_ptr] # текущая команда
if command == '+':
memory[data_ptr] += 1
elif command == '-':
memory[data_ptr] -= 1
elif command == '>':
data_ptr = (data_ptr + 1) % mem_size # циклическая память
elif command == '<':
data_ptr = (data_ptr - 1) % mem_size # циклическая память
...
instr_ptr += 1 # сдвигаеи к следующей команде
Команда точка «.» печатает на экране единственный символ из текущий ячейки памяти. Я использую функцию chr, чтобы из числа получить символ. end='' указывает, что не надо переводить строку. Команда запятая «,» вводит символ из потока ввода. Считываю строку, беру первый символ и получаю его код функцией ord. Дополним код цикла обработкой ввода и вывода:
...
elif command == '.':
# печатаем символ с кодом = значения текущей ячейки
print(chr(memory[data_ptr]), end='')
elif command == ',':
# ввод - берем код первого символа или 0, если ввод пустой
inp = input()
memory[data_ptr] = ord(inp[0]) if inp else 0
...
Это еще не все. Осталось самое сложное – обработка циклов (они же играю роль ветвлений в BF). Открывающая квадратная скобка «[« в code – команда, говорит нам, что нужно проверить текущую ячейку памяти в memory на равенство нулю. Если нуль, то прыгаем за пределы цикла – на соответствующую закрывающую скобку «]». Если не нуль, то дальше просто выполняем тело цикла. Когда натакливаемся на «]», тут тоже нужно проверить условие цикла, и если оно даст не ноль – вернуться к началу цикла, а иначе продолжить выполнять код дальше за скобкой.
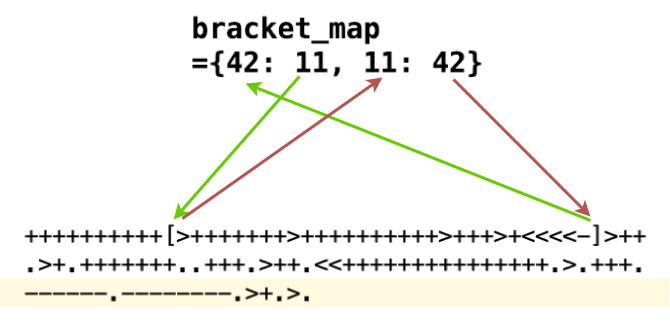
Каждый раз во время выполнения кода искать нужную скобку – неудобно и медленно. Можно оптимизировать код, заранее пройдя по нему и запомнив, где какая скобка и где ее подруга – парная скобка. Для этого заведем словарь bracket_map. Для учета вложенности будем пользоваться структурой данных – стэк (из обычного списка):
# ключ и значения - индекс байта в коде
# по любой скобке находим ей пару
bracket_map = {}
stack = []
for pos, symbol in enumerate(code):
# открыли скобку - положим на вершину стэка ее позицию
if symbol == '[':
stack.append(pos)
elif symbol == ']':
# вершина стэка - как раз наша парная скобка - была последней
# удалим ее с вершины
last_open_pos = stack.pop()
# создадим парные записи
bracket_map[pos] = last_open_pos
bracket_map[last_open_pos] = pos
На иллюстрации ниже показано, что хранит этот словарь на примере простой программы.
Теперь мы готовы добавить в цикл исполнения обработку скобок. Просто проверяем условие, и когда нужно перемещаем указатель текущий команды на парную скобку: из начала цикла в конец, если ячейка содержит 0, и из конца цикла в начало, если не 0:
...
elif command == '[':
# начало цикла - проверка текущей ячейки
if not memory[data_ptr]: # == 0
# значит надо перейти на ячейку за соответствующей ей закрывающей скобкой
instr_ptr = bracket_map[instr_ptr]
elif command == ']':
# проверяем тоже условие, если выполняется, то скачем на начало цилка
if memory[data_ptr]: # не ноль
# перемещаем на конец цикла
instr_ptr = bracket_map[instr_ptr]
Готово! Интерпретатор завершен! Выполним простую программу hello_world.bf:
++++++++++[>+++++++>++++++++++>+++>+<<<<-]>++ .>+.+++++++..+++.>++.<<+++++++++++++++.>.+++. ------.--------.>+.>.
(venv) ➜ bf python bf_interpretator.py hello_world.bf Hello World!
Работает! А вот как вам сортировка вставками на Brainfuck:
>>+>,[
<[
[>>+<<-]>[<<+<[->>+[<]]>>>[>]<<-]<<<
]>>[<<+>>-]<[>+<-]>[>>]<,
]<<<[<+<]>[>.>]
Запускаем. Пишем по очереди символы по одному, энтер после каждого. Чтобы завершить ввод массива – просто энтер без символа:
(venv) ➜ bf python bf_interpretator.py isort.bf 8 4 6 1 9 14689
Код программы и примеры загрузил на gist.
Компилятор Brainfuck на Python
Компилятор берет исходный код и превращает его в машинный исполняемый код. Не бойтесь, мы не будем писать в сложные по формату исполняемые файлы ассемблерные команды в виде байт. Поступим хитро. Сначала транслируем программу на BF в код на языке С, а потом обычным компилятором С транслируем код С в исполняемый файл.
Код обрамляется прелюдией, где мы подключаем стандартную библиотеку и инициализируем память. А также завершающими командами:
PRELUDE = """// brainfuck generated:
#include <stdio.h>
int main() {
const int mem_size = 30000;
char mem[mem_size];
memset(mem, 0, mem_size);
int cur = 0;
"""
ENDING = """
return 0;
}
"""
Далее код компилятора BF в Си. Все по таблице из Википедии:
def compile_to_c(bf_code):
instr_ptr = 0 # индекс текущей инструкции кода (code)
indent = 4 # смещение пробелами - для красоты
c_code = PRELUDE
# выполняем - пока не вылетели за пределы кода
for command in bf_code:
content = ''
if command == '+':
content = 'mem[cur]++;'
elif command == '-':
content = 'mem[cur]--;'
elif command == '>':
content = 'cur++;'
elif command == '<':
content = 'cur--;'
elif command == '.':
content = 'putchar(mem[cur]);'
elif command == ',':
content = 'mem[cur] = getchar();'
elif command == '[':
content = 'while(mem[cur]) {'
elif command == ']':
content = '}'
instr_ptr += 1 # сдвигаем к следующей команде
if content:
if command == ']':
indent -= 4
c_code += ' ' * indent + content + '\n'
if command == '[':
indent += 4
c_code += ENDING
return c_code
Сохраняем С-код на диск и вызывем компилятор cc:
c_code = compile_to_c(code)
c_file = f'{name}.c'
with open(c_file, 'w') as f:
f.write(c_code)
os.system(f'cc {c_file} -o {name}.out')
Проверка:
(venv) ➜ bf python bf_compiler.py hello_world.bf ...тут какое-то предупреждение от компилятора... (venv) ➜ bf ./hello_world.bf.out Hello World!
Код на Си получится примерно такой (я сократил его значительно, чтобы не занимать много места в статье):
// brainfuck generated:
#include <stdio.h>
int main() {
const int mem_size = 30000;
char mem[mem_size];
memset(mem, 0, mem_size);
int cur = 0;
mem[cur]++;
mem[cur]++;
mem[cur]++;
mem[cur]++;
mem[cur]++;
while(mem[cur]) {
cur++;
mem[cur]++;
mem[cur]++;
mem[cur]++;
cur++;
mem[cur]++;
cur--;
cur--;
cur--;
cur--;
mem[cur]--;
}
cur++;
mem[cur]++;
mem[cur]++;
putchar(mem[cur]);
cur++;
mem[cur]++;
putchar(mem[cur]);
mem[cur]++;
mem[cur]++;
mem[cur]++;
mem[cur]++;
mem[cur]++;
mem[cur]++;
putchar(mem[cur]);
cur++;
putchar(mem[cur]);
return 0;
}
Код компилятора в том же самом gist.
Замечания. В это варианте запятая будет работать не так, как в интерпретаторе выше. Поэтому код с сортировкой будет вести себя иначе. И второе: проверял компилятор на своей системе macOS, на Windows компилятор скорее всего не будет работать, если только вы его не запускаете из подсистемы Linux или Cygwin или подобных.
Специально для канала @pyway. Подписывайтесь на мой канал в Телеграм @pyway 👈