
В продолжение вчерашней темы, покажу, как можно визуализировать граф ссылок объектов в Python. Возможно, кому-то это поможет решить сложные моменты с использованием памяти и с организацией нетривиальных структур данных.
0) Для рисования графов понадобится graphviz Например, на MacOS вы можете установить его через Homebrew:
brew install graphviz1) Установим библиотеку objgraph:
pip install objgraph2) Использование. Пусть у нас есть такая структура данных:
x = ["test"]
x.append(x)
y = [x, [x], dict(x=x), set([1, 2, "test"])]Сохраняем граф ссылок на объекты, на которые ссылается y в файл ‘1.png’. Обратите внимание, что show_refs принимает именно список [y], а не просто y:
import objgraph
objgraph.show_refs([y], filename='1.png')Можно для каждого объекта вывести общее число ссылок на него:
objgraph.show_refs([y], refcounts=True, filename='2.png')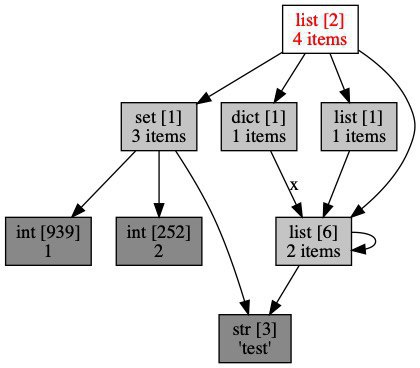
А можно узнать, кто наоборот ссылается на интересующий объект x, т.е. отследить цепочку ссылок до глобальных объектов:
objgraph.show_backrefs([x], filename='3-back.png')Узнать статистику по самым распространенным объектам в текущей среде:
>>> objgraph.show_most_common_types(limit=5)
function 2127
dict 1193
wrapper_descriptor 1002
tuple 954
weakref 868Или по конкретному типу глобально:
>>> objgraph.count('dict')
1195Или среди конкретного списка объектов:
>>> objgraph.count('dict', [{'x':5}, {'y':6}])
2В библиотеке еще много функций для отслеживания ссылок и статистик по объектам, но всего этого не вместить в небольшую заметку.
👉 Общая документация по objgraph
👉 Список функций objgraph
👨🎓Специально для канала @pyway. Подписывайтесь на мой канал в Телеграм @pyway! 👈

