
Множество (англ. «set«) – неупорядоченная коллекция из уникальных (неповторяющихся) элементов. Элементы множества в Python должны быть немутабельны (неизменяемы), хотя само содержимое множества может меняться: можно добавлять и удалять элементы из множества.
О неизменяемых множествах написано в конце этой статьи.
CPython: внутри множества реализованы как хэш-таблицы, в которых есть только ключи без значений и добавлены некоторые оптимизации, которые используют отсутствие значений. Проверка членства выполняется за время O(1), так как поиск элементов в хэш-таблицы тоже выполняется за О(1). Если интересно, как это реализовано на С: вот ссылка.
Создание множества
Сформировать множество можно несколькими способами. Самый простой – перечислить элементы через запятую внутри фигурных скобок {}. Множество может содержать элементы разных типов, главное, чтобы они были неизменяемы. Поэтому кортеж можно поместить в множество, а список – нельзя.
>>> my_set = {1, 2, 3, 4}
>>> my_hetero_set = {"abc", 3.14, (10, 20)} # можно с кортежем
>>> my_invalid_set = {"abc", 3.14, [10, 20]} # нельзя со списком
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: unhashable type: 'list'Можно также воспользоваться встроенной функцией set, чтобы создать множество из другой коллекции: списка, кортежа или словаря. Если это будет словарь – то новое множество будет составлено только из ключей этого словаря. Можно создать множество даже из строки: будет добавлена каждая буква (но только один раз):
>>> my_set2 = set([11, 22, 33])
>>> my_set2
{33, 11, 22}
>>> my_set3 = set((1, 2, 3))
>>> my_set3
{1, 2, 3}
>>> my_set4 = set({"a": 10, "b": 20})
>>> my_set4
{'b', 'a'}
>>> my_set5 = set("hello")
>>> my_set5
{'h', 'l', 'e', 'o'}Как создать пустое множество? {} – вернет нам пустой словарик, а не множество. Поэтому, нужно использовать set() без аргументов.
>>> is_it_a_set = {}
>>> type(is_it_a_set)
<class 'dict'>
>>> this_is_a_set = set()
>>> type(this_is_a_set)
<class 'set'>Изменение множеств
Множества можно менять, добавляя или удаляя элементы. Так как они не упорядочены, то индексирование не имеет смысла и не поддерживается: мы не может получать доступ к элементам множества по индексу, как мы это делаем для списков и кортежей.
Добавление одного элемента выполняется методом add(). Нескольких элементов из коллекции или нескольких коллекций – методом update():
>>> my_set = {44, 55}
>>> my_set.add(50)
>>> my_set
{50, 44, 55}
>>> my_set.update([1, 2, 3])
>>> my_set
{1, 2, 3, 44, 50, 55}
>>> my_set.update([2, 3, 6], {1, 50, 60})
>>> my_set
{1, 2, 3, 6, 44, 50, 55, 60}
>>> my_set.update("string")
>>> my_set
{1, 2, 3, 6, 'i', 44, 'r', 50, 's', 55, 'n', 'g', 60, 't'}Естественно, что при добавлении элементов дубликаты игнорируются.
Удаление элементов из множества
Для удаления элемента существуют методы discard() и remove(). Делают они одно и тоже, но если удаляемого элемента нет во множестве, то discard() оставит множество неизменным молча, а remove() – бросит исключение:
>>> my_set = {1, 2, 3, 4, 5, 6}
>>> my_set.discard(2)
>>> my_set
{1, 3, 4, 5, 6}
>>> my_set.remove(4)
>>> my_set
{1, 3, 5, 6}
>>> my_set.discard(10)
>>> my_set
{1, 3, 5, 6}
>>> my_set.remove(10)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
KeyError: 10Также есть метод pop(), который берет какой-нибудь (первый попавшийся) элемент множества, удаляет его и возвращает как результат:
>>> my_set = {3, 4, 5, 6, 1, 2}
>>> my_set
{1, 2, 3, 4, 5, 6}
>>> my_set.pop()
1
>>> my_set
{2, 3, 4, 5, 6}Наконец, очистить множество (т.е. удалить все его элементы) можно методом clear():
>>> my_set = {1, 2, 3}
>>> my_set.clear()
>>> my_set
set()Проверка членства
Узнать есть ли элемент в множестве очень легко оператором in (или not in, если хотим убедиться в отсутствии элемента):
>>> s = {"banana", "apple"}
>>> "banana" in s
True
>>> "tomato" not in s
TrueТаким образом проверяется членства одного элемента, если нужно узнать является ли одно множество подмножеством другого, то оператор in тут не подойдет:
>>> {1, 2} in {1, 2, 3}
FalseТут подойдут операторы < и >. Чтобы получить True, с «широкой» стороны оператора должно стоять множество, полностью содержащее множество, стоящее по «узкую» сторону галочки:
>>> {1, 2} < {1, 2, 3, 4}
True
>>> {5, 6, 7, 8} > {5, 8}
True
>>> {1, 2, 3} < {1, 2, 4}
FalseИтерация множеств
Пробежаться по элементам множества также легко, как и по элементам других коллекций оператором for-in (порядок обхода не определен точно):
my_set = {"Moscow", "Paris", "London"}
for elem in my_set:
print(elem)
Moscow
London
ParisОперации над множествами
Самое интересное – проводить математические операции над множествами.
Рассмотрим два множества A и B:
A = {1, 2, 3, 4, 5}
B = {4, 5, 6, 7, 8}Объединение
Объединение множеств – множество, в котором есть все элементы одного и другого множеств. Это коммуникативная операция (от перемены мест ничего не меняется).
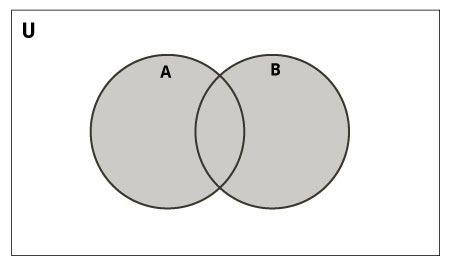
В Python используется либо метод union(), либо оператор вертикальная черта «|»:
>>> A = {1, 2, 3, 4, 5}
>>> B = {4, 5, 6, 7, 8}
>>> A | B
{1, 2, 3, 4, 5, 6, 7, 8}
>>> A.union(B)
{1, 2, 3, 4, 5, 6, 7, 8}
>>> B.union(A)
{1, 2, 3, 4, 5, 6, 7, 8}Пересечение множеств
Пересечение множеств – множество, в которое входят только общие элементы, то есть которые есть и в первом, и во втором множестве. Также коммуникативная операция.
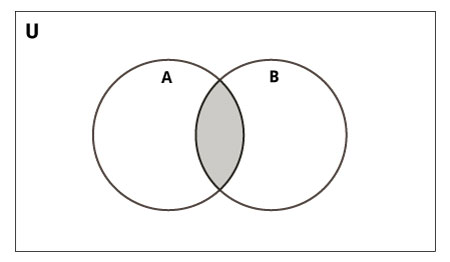
Пересечение вычисляют методом intersection() или оператором амперсандом «&»:
>>> A = {1, 2, 3, 4, 5}
>>> B = {4, 5, 6, 7, 8}
>>> A & B
{4, 5}
>>> B & A
{4, 5}
>>> A.intersection(B)
{4, 5}Разность множеств
Разность множеств A и В – множество элементов из A, которых нет в B. Не коммуникативная операция!
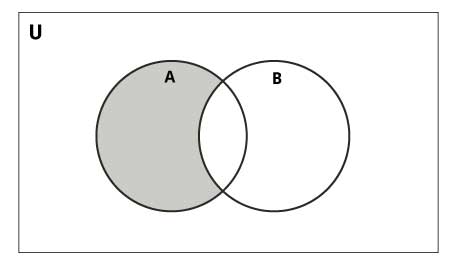
Выполняется знаком минус «-» или оператором difference():
>>> A = {1, 2, 3, 4, 5}
>>> B = {4, 5, 6, 7, 8}
>>> A - B
{1, 2, 3}
>>> B - A
{8, 6, 7}
>>> A.difference(B)
{1, 2, 3}
>>> B.difference(A)
{8, 6, 7}Как видно есть разница, в каком порядке идут операнды.
Симметричная разность
Симметричная разность – это объединение множеств за исключеним их пересечения. По другому, это сумма разностей. Это коммуникативный оператор.
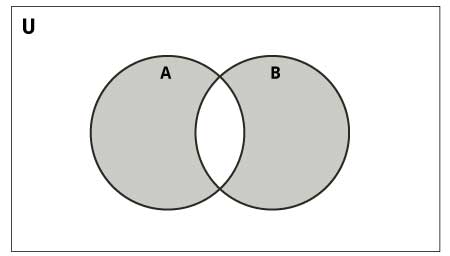
Используется метод symmetric_difference() или оператор крышка «^»:
>>> A = {1, 2, 3, 4, 5}
>>> B = {4, 5, 6, 7, 8}
>>> A ^ B
{1, 2, 3, 6, 7, 8}
>>> B ^ A
{1, 2, 3, 6, 7, 8}
>>> A.symmetric_difference(B)
{1, 2, 3, 6, 7, 8}Обратите внимание на эквивалентность операции определениям, которые я привел в начале этого раздела:
>>> A ^ B == (A - B) | (B - A) # объединение простых разностей
True
>>> A ^ B == (A | B) - (A & B) # разность объединения и пересечения
TrueПрочее
Ко множествам можно применять стандартные функции all(), any(), enumerate(), len(), max(), min(), sorted(), sum(). Описания их ищите тут.
Прочие методы класса set:
| copy() | Возвращает копию множества |
| difference_update(other_set) | Удаляет из этого множества все элементы, которые есть во множестве, переданным в аргументе |
| intersection_update(other_set) | Обновляет это множество элементами из пересечения множеств |
| isdisjoint(other_set) | Возвращает True, если множества не пересекаются |
| issubset(other_set) | Возвращает True, если это множество является подмножеством другого |
| issuperset(other_set) | Возвращает True, если это множество является надмножеством другого |
| symmetric_difference_update(other_set) | Добавляет в это множество симметричную разность этого и другого множеств |
Замороженное множество
Замороженное множество (frozen set) также является встроенной коллекцией в Python. Обладая характеристиками обычного множества, замороженное множество не может быть изменено после создания (подобно тому, как кортеж является неизменяемой версией списка).
Будучи изменяемыми, обычные множества являются нехешируемыми (unhashable type), а значит не могут применятся как ключи словаря или элементы других множеств.
Замороженные множества являются хэшируемыми, а значит могут быть ключами словаря и элементами других множеств.
Создаются замороженные множества функцией frozenset(), где аргументом будет другая коллекция. Примеры:
>>> A = frozenset({1, 2, 3})
>>> A
frozenset({1, 2, 3})
>>> B = frozenset(['a', 'b', 'cd'])
>>> B
frozenset({'cd', 'b', 'a'})Над замороженными множествами можно производить все вышеописанные операции, кроме тех, что изменяют содержимое этого множества. Причем результатом логических операций будут тоже замороженные множества:
>>> A = frozenset('hello')
>>> B = frozenset('world')
>>> A | B
frozenset({'o', 'r', 'd', 'e', 'l', 'h', 'w'})
>>> A & B
frozenset({'o', 'l'})
>>> A ^ B
frozenset({'d', 'e', 'h', 'r', 'w'})Теперь вы знаете много о множествах в Python.
Специально для канала @pyway. Подписывайтесь на мой канал в Телеграм @pyway 👈



{kind=link}