Программисты так или иначе тестируют свои программы. В простых случаях можно запустить программу несколько раз и проверить результаты. А если вы внесли изменение? Нужно проделать эту рутинную работу еще раз и не ошибиться самому. В сложных программах это просто нереально. Естественно, этот процесс автоматизируется. Сложная программа состоит из отдельных классов, функций и модулей, каждый из которых отвечает за свой ограниченный круг функциональности. Поэтому разумно написать несколько небольших программок, которые будут подавать на вход разнообразные типичные комбинации данных и сравнивать с ожидаемым результатом. Это и будут юнит-тесты. После изменения кода запуск юнит-тестов покажет, не сломалось ли поведение программы.
В Python поставляется модуль unittest, который облегчает написание тестов:
- Обнаружение и автоматическое исполнение тестов
- Настройка теста и его завершение
- Группирование тестов
- Статистика тестирования
Чтобы создать тестовый случай, нужно создать класс, отнаследованный от unittest.TestCase. А внутри этого класса можно добавить несколько методов, начинающихся со слова test. Каждый из этих методов должен тестировать какой-то из аспектов кода. Для примера мы тестируем свойства строк Python: сложение строк (test_sum) и преобразование к нижнему регистру (test_lower):
import unittest
class StringTestCase(unittest.TestCase):
def test_sum(self):
self.assertEqual("" + "", "")
self.assertEqual("foo" + "bar", "foobar")
def test_lower(self):
self.assertEqual("FOO".lower(), "foo")
self.assertTrue("foo".islower())
self.assertFalse("Bar".islower())
Самые распространенные проверки:
self.assertEqual – непосредственно проверяет, чтобы первый аргумент равнялся второму. Если это будет не так, то тест будет провален, и появится сообщение о том, что и где пошло не так.
self.assertTrue – ожидает, что аргумент будет эквивалентен правде (True), а self.assertFalse – проверяет на ложь (False).
Запуск делается либо непосредственно из самой программы:
if name == '__main__':
unittest.main()
А можно из консоли:
python -m unittest my_test.py
Модуль unittest сам найдет все тестовые случаи и выполнит в них все тестовые функции.
Фикстуры
Тестовые фикстуры (test fixtures) – особые условия, которые создаются для выполнения тестов. Сюда могут входить такие вещи:
- Подготовка тестовых данных
- Создание подключений к БД, сервисам и т.п.
- Создание заглушек (mock) для имитации компонентов программы
- Другие действия по поддержке рабочего окружения для проведения теста
Пример: у вас программа, которая вычисляет вычисляет число π до n-знака, и вам нужно протестировать, как будет выведен на экран миллионнный знак. Вы же не будете в тесте ждать вычисления всех предыдущих 999,999 знаков часами, а просто загрузите какие-то данные в память, чтобы создать условия, как будто мы уже на миллионом знаке.
В unittest фикстуры можно создавать на уровне модуля с тестами, отдельного класса (от unittest.TestCase) и каждого метода в классе теста.
Метод setUp() вызывается перед каждым вызовом метода test* в классе тестового случая.
Классовый метод setUpClass() вызывается один раз перед запуском тестов в классе тестового случая.
Функция setUpModule() вызывается перед выполнением тестовых случаев в этом модуле.
У них есть пары, предназначенные для освобождения ресурсов (закрытия соединений, удаления временных файлов и т.п.):
tearDown() – после каждого метода-теста в классе. tearDownClass() – после всех тестов в классе.tearDownModule() – после всех классов в модуле.
📎 В примере изучим порядок вызовов этих функций:
import unittest
class StringTestCase(unittest.TestCase):
@classmethod
def setUpClass(cls):
print(' - set up class')
def setUp(self):
print(' - - set up method')
self.foo = "foo"
self.bar = "bar"
def test_sum(self):
self.assertEqual(self.foo + self.bar, "foobar")
def test_lower(self):
self.assertTrue(self.foo.islower())
def tearDown(self):
print(' - - tear down method')
@classmethod
def tearDownClass(cls):
print(' - tear down class')
def setUpModule():
print('set up module')
def tearDownModule():
print('tear down module')
if name == '__main__':
unittest.main()
Даст такую схему вызовов:
set up module - set up class - - set up method - - tear down method - - set up method - - tear down method - tear down class tear down module
Даже если в одной из этих или тестовых функций произошло исключение, то прочие методы tearDown*() будут все равно запущены, чтобы освобождение ресурсов произошло корректно.
Пропуск тестов
Модуль unittest поддерживает пропуск отдельных тестовых методов и целых тестовых классов. Пропускают тесты, если нет нужного ресурса для теста, тест предназначен только для отдельных платформ или версий библиотек и т.п. Способы пропустить тест:
@unittest.skip("причина")– всегда пропускать тест.@unittest.skipIf(условие, "причина")– пропускать тест, если условие сработало (True).@unittest.skipUnless(условие, "причина")– пропускать тест, если условие НЕ сработало (False).self.skipTest("причина")– если нужно остановить выполнение метода, выйти из него и не учитывать его в результатах. Так же может быть вызван в методеsetUp(), который вызывается перед каждым тестовым методом.
📎 Пример:
class MyTestCase(unittest.TestCase):
@unittest.skip("всегда пропустить")
def test_nothing(self):
self.fail("не случится")
@unittest.skipIf(mylib.__version__ < (1, 3),
"эта версия библиотеки не поддерживается")
def test_format(self):
# этот тест работает только для определенных версий
pass
@unittest.skipUnless(sys.platform.startswith("win"), "надо Windows")
def test_windows_support(self):
# тест работает только на Windows
pass
def test_maybe_skipped(self):
if not external_resource_available():
self.skipTest("ресурс недоступен")
# код дальше будет тестировать, если ресурс доступен
pass
📎 Пример пропуска класса:
@unittest.skip("как пропустить класс")
class MySkippedTestCase(unittest.TestCase):
def test_not_run(self):
pass
Вы можете написать свой декоратор. Например, данный декоратор пропускает тест, если объект obj не имеет атрибут attr:
def skipUnlessHasattr(obj, attr):
if hasattr(obj, attr):
return lambda func: func
return unittest.skip("{!r} не имеет {!r}".format(obj, attr))
class SkipAttrTestCase(unittest.TestCase):
@skipUnlessHasattr(mylib, "foofunc")
def test_with_foofunc():
# у mylib нет атрибута foofunc, тест будет пропущен
pass
Еще один декоратор @unittest.expectedFailure говорит системе тестирования, что следующий метод должен провалиться (один из self.assert должен не сработать). Таким образом, разработчик говорит, что он осведомлен, что данный тест пока проваливается, и в будущем к этому примут меры.
class ExpectedFailureTestCase(unittest.TestCase):
@unittest.expectedFailure
def test_fail(self):
self.assertEqual(1, 0, "сломано")
В конце выполнения будут счетчики пропусков и ожидаемых провалов тестов:
OK (skipped=5, expected failures=1)Проверки
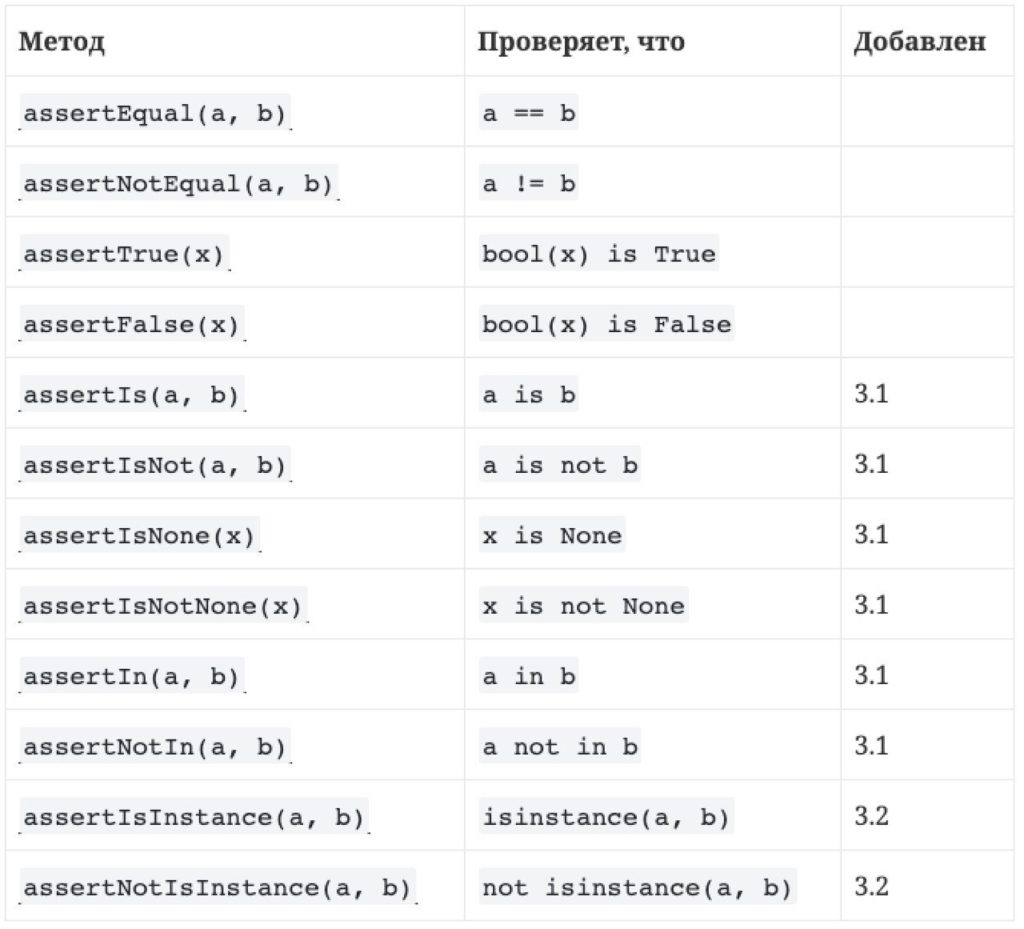
В первой части мы обсудили методы проверки assertEqual, assertTrue и assertFalse, так как они самые распространенные на практике. Вообще достаточно одного assertTrue. Действительно, одно и тоже:
assertNotIn(item, list) assertTrue(item not in list)
Поэтому не буду особо акцентировать внимание на каждом из методов, а прикреплю общую таблицу. Помимо данных для проверки, все методы могут быть дополнены сообщением, которое будет выведено в отчет, если проверка провалилась:
self.assertEqual(2 + 2, 5, "я не учил математику")
Однако, стоит упомянуть метод self.assertRaises(SomeException), который проверяет, возбуждает ли код нужное исключение. Обычно он применяется как контекст-менеджер (с with).
📎 Пример: деление на 0 должно бросать исключение ZeroDivisionError:
import unittest
def my_div(a, b):
return a // b
class MyDivTestCase(unittest.TestCase):
def test_1(self):
self.assertEqual(my_div(10, 2), 5)
# при делении на 0 ждем исключение:
with self.assertRaises(ZeroDivisionError):
my_div(7, 0)
# или так: исключение, ф-ция, аргументы
self.assertRaises(ZeroDivisionError, my_div, 5, 0)
unittest.main()
Если из исключения нужно извлечь данные (к примеру, код ошибки), то делают так:
with self.assertRaises(SomeException) as cm:
do_something()
self.assertEqual(cm.exception.error_code, 3)
PyTest
Ранее мы обсуждали тестирование средствами встроенного модуля unittest. Естественно, есть и сторонние библиотеки для тестирования. Например, библиотека PyTest предоставляет более лаконичный и удобный инструментарий для написания тестов. Однако, ее нужно установить:
pip install pytest
Преимущества PyTest:
- Краткий и красивый код
- Только один стандартный assert
- Подробный отчет
- Разнообразие фикстур на всех уровнях
- Плагин и интеграции с другими системами
Сравните этот код с кодом из предыдущих постов про unittest:
import pytest
def setup_module(module):
#init_something()
pass
def teardown_module(module):
#teardown_something()
pass
def test_upper():
assert 'foo'.upper() == 'FOO'
def test_isupper():
assert 'FOO'.isupper()
def test_failed_upper():
assert 'foo'.upper() == 'FOo'
Для тестов можно применять и классы (как в unittest), так и отдельные функции.
Запускать тесты тоже просто. В окружении, где установлен pytest, появится команда py.test. Из терминала пишем:
py.test my_test_cases.py
py.test обнаружит и выполнит тесты из этого файла.
Есть очень хорошая статья на Хабре про PyTest на русском, не вижу смысла дублировать ее сюда, а просто оставлю ссылку.
😈 Специально для канала @pyway. Подписывайтесь на мой канал в Телеграм @pyway 👈