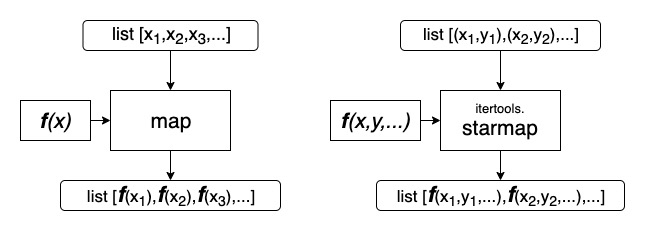
Встроенная функция map принимает функцию и итерируемый объект, а возвращает тоже итератор, применяя ту функцию к каждому элементу исходного итератора. А, чтобы получить список, мы извлекаем из итератора все значения, приведя его к списку функцией list. Пример map: прибавлятор единички ко всем элементам массива:
>> list(map(lambda x: x + 1, [1, 2, 3, 4])) [2, 3, 4, 5]
Что делать, если нужно применить функцию, которая принимает большее количество аргументов? Например, возведение в степень pow принимает основание и показатель:
>>> pow(2, 4) 16
Как и требуют, мы даем в map функцию с одним аргументом, но каждый элемент t – кортеж из двух элементов, мы распаковываем его в аргументы pow звездочкой:
>>> list(map(lambda t: pow(*t), [(2, 4), (3, 2), (5, 2)])) [16, 9, 25]
Если вы не знали: pow(*t) то же самое, что и pow(t[0], t[1]), если в t два элемента.
К счастью, не обязательно делать этот хак с лямбдой, потому что в модуле itertools есть функция starmap, которая как раз звездочкой распаковывает каждый элемент исходного итератора в аргументы функции:
>>> from itertools import starmap >>> list(starmap(pow, [(2, 4), (3, 2), (5, 2)])) [16, 9, 25]
🐉 Специально для канала @pyway. Подписывайтесь на мой канал в Телеграм @pyway 👈