
super() – это встроенная функция языка Python. Она возвращает прокси-объект, который делегирует вызовы методов классу-родителю (или собрату) текущего класса (или класса на выбор, если он указан, как параметр).
Основное ее применение и польза – получения доступа из класса наследника к методам класса-родителя в том случае, если наследник переопределил эти методы.
Что такое прокси-объект? Прокси, по-русски, это заместитель. То есть это объект, который по смыслу должен вести себя почти так же, как замещенный объект. Как правило он перенаправляет вызовы своих методов к другому объекту.
Давайте рассмотрим пример наследования. Есть какой-то товар в классе Base с базовой ценой в 10 единиц. Нам понадобилось сделать распродажу и скинуть цену на 20%. Хардкодить – это непрофессионально и негибко:
class Base:
def price(self):
return 10
class Discount(Base):
def price(self):
return 8
Гораздо лучше было бы получить цену из родительского класса Base и умножить ее на коэффициент 0.8, что даст 20% скидку. Однако, если мы вызовем self.price() в методе price() мы создадим бесконечную рекурсию, так как это и есть один и тот же метод класса Discount! Тут же нужен метод Base.price(). Тогда его и вызовем по имени класса:
class Discount(Base):
def price(self):
return Base.price(self) * 0.8
Здесь, надо не забыть указать self при вызове первым параметром явно, чтобы метод был привязан к текущему объекту. Это будет работать, но этот код не лишен изъянов, потому что необходимо явно указывать имя предка. Представьте, если иерархия классов начнет разрастаться? Например, нам нужно будет вставить между этими классами еще один класс, тогда придется редактировать имя класса-родителя в методах Discount:
class Base:
def price(self):
return 10
class InterFoo(Base):
def price(self):
return Base.price(self) * 1.1
class Discount(InterFoo): # <--
def price(self):
return InterFoo.price(self) * 0.8 # <--
Тут на помощь приходит super()! Супер он не потому что, подобно Супермэну, помогает всем людям, а потому что обращается к атрибутам классов стоящих над ним в порядке наследования (кто учил матан, вспомнят понятие супремум).
Будучи вызванным без параметров внутри какого-либо класса, super() вернет прокси-объект, методы которого будут искаться только в классах, стоящих ранее, чем он, в порядке MRO. То есть, это будет как будто бы тот же самый объект, но он будет игнорировать все определения из текущего класса, обращаясь только к родительским:
class Base:
def price(self):
return 10
class InterFoo(Base):
def price(self):
return super().price() * 1.1
class Discount(InterFoo):
def price(self):
return super().price() * 0.8
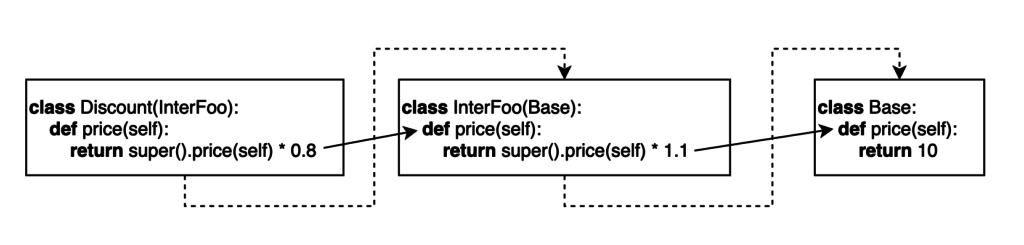
Для Discount порядок MRO: Discount - InterFoo - Base - object. Вызов super().method() внутри класса Discount будет игнорировать Discount.method(), а будет искать method в InterFoo, затем, если не найдет, то в Base и object.
Когда нельзя забыть super?
Очень часто super вызывается в методе __init__. Метод инициализации класса __init__, как правило задает какие-либо атрибуты экземпляра класса, и если в дочернем классе мы забудем его вызвать, то класс окажется недоинициализированным: при попытке доступа к родительским атрибутам будет ошибка:
class A:
def __init__(self):
self.x = 10
class B(A):
def __init__(self):
self.y = self.x + 5
# print(B().y) # ошибка! AttributeError: 'B' object has no attribute 'x'
# правильно:
class B(A):
def __init__(self):
super().__init__() # <- не забудь!
self.y = self.x + 5
print(B().y) # 15
Параметры super
Функция может принимать 2 параметра. super([type [, object]]). Первый аргумент – это тип, к предкам которого мы хотим обратиться. А второй аргумент – это объект, к которому надо привязаться. Сейчас оба аргумента необязательные. В прошлых версиях Python приходилось их указывать явно:
class A:
def __init__(self, x):
self.x = x
class B(A):
def __init__(self, x):
super(B, self).__init__(x)
# теперь это тоже самое: super().__init__(x)
Теперь Python достаточно умен, чтобы самостоятельно подставить в аргументы текущий класс и self для привязки. Но старая форма тоже осталась для особых случаев. Она нужна, если вы используете super() вне класса или хотите явно указать с какого класса хотите начать поиск методов.
Действительно, super() может быть использована вне класса. Пример:
d = Discount() print(super(Discount, d).price())
В этом случае объект, полученный из super(), будет вести себя как класс InterFoo (родитель Discount), хотя привязан он к переменной d, которая является экземпляром класса Discount.
Это редко используется, но, вероятно, кому-то будет интересно узнать, что функция super(cls), вызванная только с одним параметром, вернет непривязанный к экземпляру объект. У него нельзя вызывать методы и обращаться к атрибутам. Привязать его можно будет так:
super_d = super(Discount) d = Discount() binded_d = super_d.__get__(d, Discount) # привязка print(binded_d.price()) # 11.0
Множественное наследование
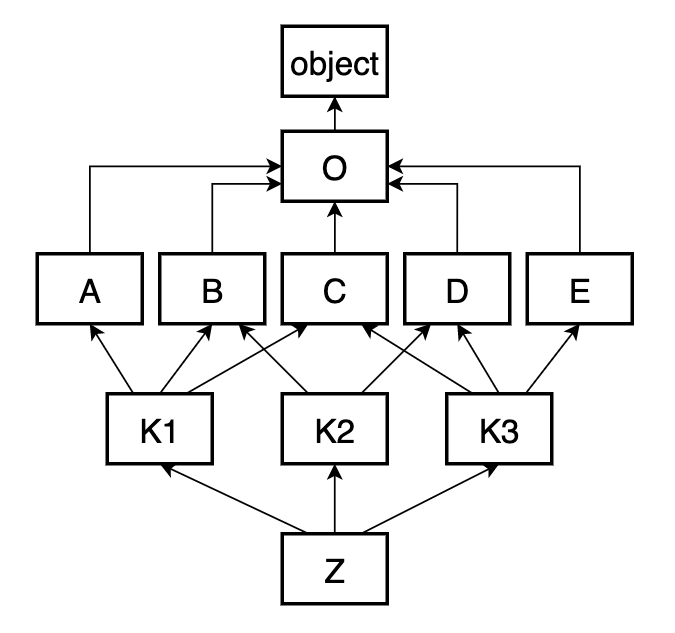
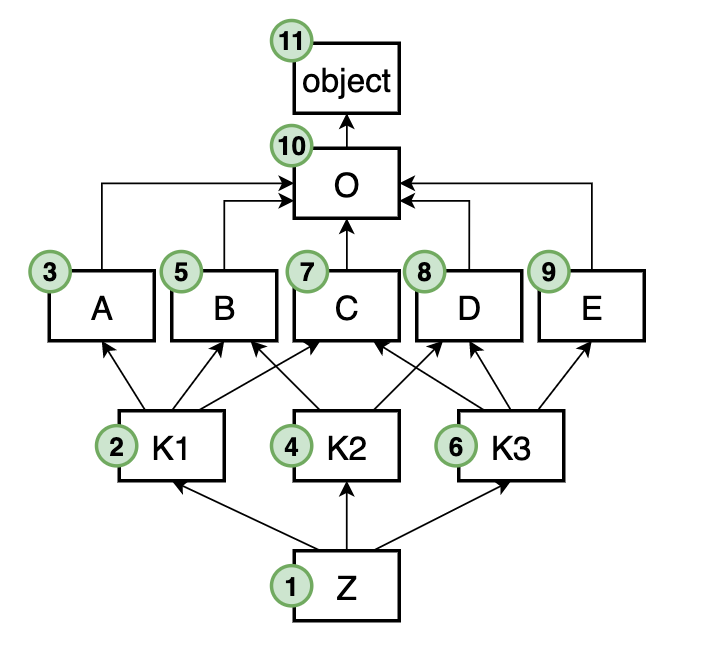
В случае множественного наследования super() необязательно указывает на родителя текущего класса, а может указывать и на собрата. Все зависит от структуры наследования и начальной точки вызова метода. Общий принцип остается: поиск начинается с предыдущего класса в списке MRO. Давайте рассмотрим пример ромбовидного наследования. Каждый класс ниже в методе method печатает свое имя. Плюс все, кроме первого, вызывают свой super().method():
class O:
def method(self):
print('I am O')
class A(O):
def method(self):
super().method()
print('I am A')
class B(O):
def method(self):
super().method()
print('I am B')
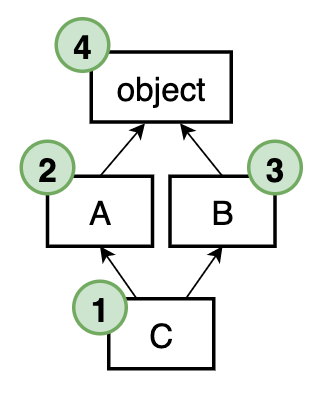
class C(A, B):
def method(self):
super().method()
print('I am C')
Если вызвать метод C().method(), то в терминале появится такая распечатка:
# C().method() I am O I am B I am A I am C
Видно, что каждый метод вызывается ровно один раз и ровно в порядке MRO. C вызывает родителя A, а A вызывает своего брата B, а B вызывает их общего родителя O. Но! Стоит нам вызвать A().method(), он уже не будет вызывать B().method(), так как класса B нет среди его родителей, он брат, а родитель у класс А только один – это O. А о братьях он и знать не хочет:
# A().method() I am O I am A
Таким образом, вызов super() сам автоматически догадывается, к кому обращаться: к родителю или к брату. Все зависит от иерархии класса и начальной точки вызова. Эта фишки снимают с программиста головную боль, связанную с заботой о поддержании цепочки вызовов в иерархии классов.
Специально для канала @pyway. Подписывайтесь на мой канал в Телеграм @pyway 👈

{kind=link}