
Как понять насколько близки две строки? Как поисковая система все равно находит то, что надо, даже если вы совершили пару опечаток в запросе? В этом вопросе нам поможет расстояние по Левенштейну или редакционное расстояние. Почему редакционное? Потому что мы считаем, сколько действий по редактированию одной строки нужно совершить, чтобы получить другую строку. Действия бывают следующими: вставка символа, удаление символа и замена одного символа другим.
Одинаковые строки имеют нулевое расстояние: не нужно ничего редактировать, первая и так равна второй. «Привет» и «Привт» имеют расстояние 1 (пропущена одна буква, остальное не изменилось). «Привет» и «привты» имеют расстояние 3 (одна замена «П» на «п», удаление буквы «е» и вставка «ы» на конце). Мы будем считать
Я не буду сюда копировать теорию и тем более доказательства, это вы можете изучить в Вики.
Давайте попробуем реализовать этот алгоритм в лоб по формуле:
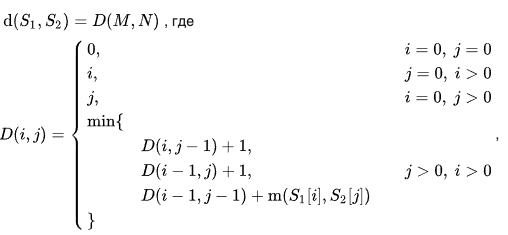
Функция m – возвращает единицу, если символы не равны, иначе 0. Вот такой код получится:
def my_dist(a, b):
def recursive(i, j):
if i == 0 or j == 0:
# если одна из строк пустая, то расстояние до другой строки - ее длина
# т.е. n вставок
return max(i, j)
elif a[i - 1] == b[j - 1]:
# если оба последних символов одинаковые, то съедаем их оба, не меняя расстояние
return recursive(i - 1, j - 1)
else:
# иначе выбираем минимальный вариант из трех
return 1 + min(
recursive(i, j - 1), # удаление
recursive(i - 1, j), # вставка
recursive(i - 1, j - 1) # замена
)
return recursive(len(a), len(b))
Вспомогательная функция, чтобы протестировать производительность:
from timeit import timeit
def test_lev_dist(f: callable, a, b, n=1):
tm = timeit("f(a, b)", globals={
'f': f, 'a': a, 'b': b
}, number=n)
r = f(a, b)
print(f'a = {a!r} and b = {b!r} and {f.__name__} = {r} and time = {tm:.4f}')
test_lev_dist(my_dist, "hello world", "bye world!")
# a = 'hello world' and b = 'bye world!' and my_dist = 6 and time = 1.3829
Как можете видеть, первый вариант кода работает экстремально медленно, потому что много раз вычисляет функцию при одних и тех же входных параметрах. Давайте узнаем, сколько раз вызывается внутренняя функция. Для этого добавим декоратор, который считает число вызовов:
def count_calls(f):
@wraps(f)
def wrapped(*args, **kwargs):
wrapped.n_calls += 1
return f(*args, **kwargs)
wrapped.n_calls = 0
return wrapped
def my_dist(a, b):
@count_calls
def recursive(i, j):
... # прочий код пропущен
r = recursive(len(a), len(b))
print('calls =', recursive.n_calls)
return r
my_dist("hello world", "bye world!")
# calls = 3317804
Более 3 миллионов вызовов! И большинство из них с одинаковыми параметрами. А так как они повторяются, то можно их закешировать (при помощи lru_cache). Здесь размер кэша примерно равен числу различных комбинаций входных параметров.
from functools import lru_cache
def my_dist_cached(a, b):
@count_calls
@lru_cache(maxsize=len(a) * len(b))
def recursive(i, j):
if i == 0 or j == 0:
return max(i, j)
elif a[i - 1] == b[j - 1]:
return recursive(i - 1, j - 1)
else:
return 1 + min(
recursive(i, j - 1),
recursive(i - 1, j),
recursive(i - 1, j - 1)
)
r = recursive(len(a), len(b))
print('calls = ', recursive.n_calls)
return r
my_dist_cached("hello world", "bye world!")
# calls = 212
Количество вызовов сократилось до 212, а скорость работы увеличилась на порядки. Выкинем count_calls и проведем замеры времени для 10000 повторных вызовов.
def my_dist_cached(a, b):
@lru_cache(maxsize=len(a) * len(b))
def recursive(i, j):
if i == 0 or j == 0:
return max(i, j)
elif a[i - 1] == b[j - 1]:
return recursive(i - 1, j - 1)
else:
return 1 + min(
recursive(i, j - 1),
recursive(i - 1, j),
recursive(i - 1, j - 1)
)
return recursive(len(a), len(b))
test_lev_dist(my_dist_cached, "hello world", "bye world!", n=10000)
# a = 'hello world' and b = 'bye world!' and my_dist_cached = 6 and time = 0.9740
Производительность улучшилась радикально (в прошлый раз мы прогоняли один вызов функции, а теперь 10000 раз, и то выходит быстрее). Однако, пока что объем требуемой памяти растет как O(len(a) * len(b)). Иными словами, для двух мегабайтных строк потребуются гигабайты памяти. Фактически в кэше будет хранится почти все матрица редактирований, а она нам не нужна целиком. Наша цель – правый нижний элемент.
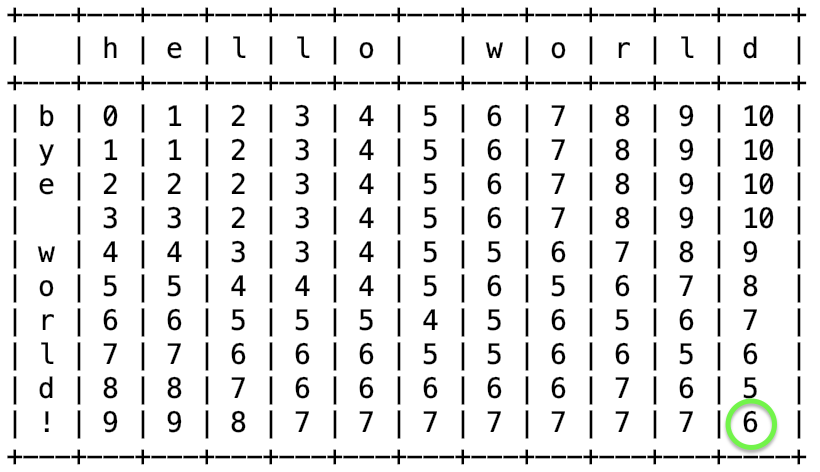
Для его поиска можно обойтись лишь парой рядов: текущим и предыдущим. А остальные ряды не хранить в памяти. Так мы дойдем до конца таблицы, и нижний правый угол и будет искомым значением.
Вот пример реализации:
def distance(a, b):
n, m = len(a), len(b)
if n > m:
# убедимся что n <= m, чтобы использовать минимум памяти O(min(n, m))
a, b = b, a
n, m = m, n
current_row = range(n + 1) # 0 ряд - просто восходящая последовательность (одни вставки)
for i in range(1, m + 1):
previous_row, current_row = current_row, [i] + [0] * n
for j in range(1, n + 1):
add, delete, change = previous_row[j] + 1, current_row[j - 1] + 1, previous_row[j - 1]
if a[j - 1] != b[i - 1]:
change += 1
current_row[j] = min(add, delete, change)
return current_row[n]
Объяснение. Сначала, чтобы использовать еще меньше памяти, мы можем поменять местами наши строки, чтобы длина рядов была минимальна. Это существенно экономит память, если одна из строк длинная, а другая короткая.
Затем мы понимаем, что нулевой ряд или столбец матрицы – просто восходящая последовательность. Потому что, чтобы из пустой строки получить любую не пустую, нужно ровно то число вставок, сколько символов в не пустой строке. И наоборот: n удалений из строки длины n приведут неизбежно к пустой строке.
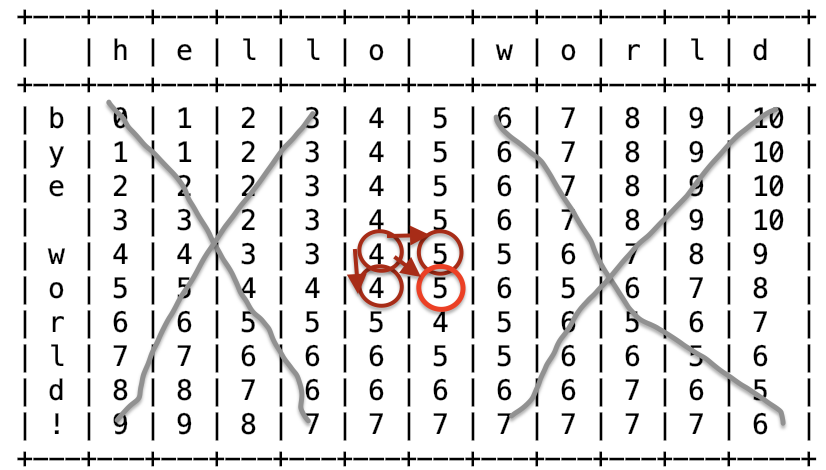
Потом мы шагаем по рядам матрицы, помня только текущий ряд и предыдущий, мы заполняем неизвестные клетки текущего ряда. Соседние клетки отвечают за вставку одного символа, удаление или замену (если символы неравны). Из трех возможных изменений мы выбираем то, чья стоимость наименьшая.
Эта версия еще быстрее, чем кэшированная:
test_lev_dist(distance, "hello world", "bye world!", n=10000) # a = 'hello world' and b = 'bye world!' and distance = 6 and time = 0.7374
Сложность этого алгоритма растет как произведение длин строк: O(n*m). Это еще не самый эффективный алгоритм. Для дальнейшего ускорения нужно воспользоваться древовидной структурой данных. Также неплохо бы учесть то, что на известном словаре можно заранее вычислить расстояния между словами.
Наконец-то, когда мы разобрались с принципом работы алгоритма, вспомним, что все велосипеды уже написаны до нас, да еще и на языке Си. Воспользуемся библиотечными функциями, установив пакет:
pip install python-Levenshtein
import Levenshtein test_lev_dist(Levenshtein.distance, "hello world", "bye world!", n=10000) # a = 'hello world' and b = 'bye world!' and distance = 6 and time = 0.0032
Специально для канала @pyway. Подписывайтесь на мой канал в Телеграм @pyway 👈