
Для оформления информации в терминале часто нужно знать размеры окна терминала (количество колонок и строк). Во встроенном модуле shutil можно найти функцию get_terminal_size, которая возвращает именованный кортеж:
>>> shutil.get_terminal_size() os.terminal_size(columns=208, lines=25)
Или
>>> cols, lines = shutil.get_terminal_size() >>> cols, lines (208, 25)
Или
>>> tsz = shutil.get_terminal_size() >>> tsz.columns, tsz.lines (208, 25)
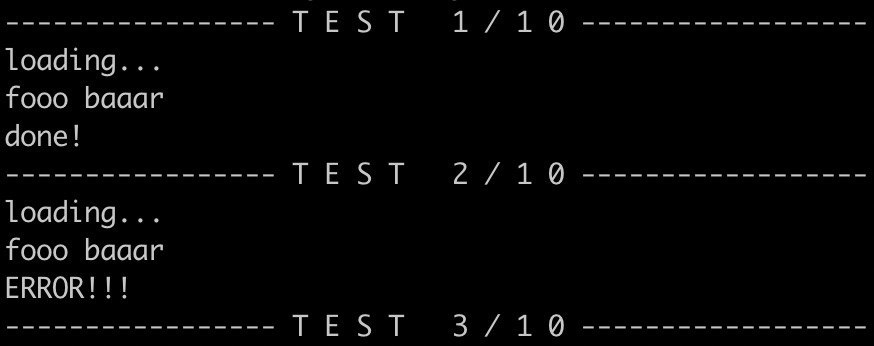
Например, сделаем разделитель с заголовком, как на фото.
1. Будем форматировать по центру значение в строку с заданной длинной, а пустые места заполнить каким-то символом. Для этого нужен особый формат:
>>> '{:^10}'.format('love')
' love '
>>> '{:-^10}'.format('life')
'---life---'
Знак после двоеточия – заполнитель (если его нет, то пробел); а число после крышечки – желаемая ширина строки. Крышечка указывает, что форматирование будет по центру.
2. Так как число неизвестно заранее, то его тоже надо вставить с помощью format, предварительно экранировав фигурные скобки (двойная фигурная скобка в формате воспринимается как соотвествующий символ, а не как место для подстановки):
>>> '{{:-^{}}}'.format(10)
'{:-^10}'
>>> '{{:-^{}}}'.format(10).format('love')
'---love---'
>>> '{{:-^{}}}'.format(shutil.get_terminal_size().columns).format('love')
'---------------------------love----------------------------'
3. Текст, что по центру сделаем заглавным, а также каждый символ отделим пробелами, чтобы заголовок казался заметнее:
>>> ' '.join('love'.upper())
'L O V E'
>>> ' ' + ' '.join('love'.upper()) + ' '
' L O V E '
4. Соеденим все вместе в однострочник, добавив print к итоговой строке:
def sep(s):
print('{{:-^{}}}'.format(shutil.get_terminal_size().columns).format(' ' + ' '.join(str(s).upper()) + ' '))
Хочу уточнить, что shutil.get_terminal_size() не всегда способна определить размер терминала. Например, когда собственно и нет никакого окна терминала, а лишь есть поток вывода как при выводе в файл или в канал. У потока вывода нет таких характеристик как размер окна. При выполнении функции в среде PyCharm функция вернет размер по умолчанию (80 на 25), и разделитель будет не на всю ширину области вывода, если она шире 80 символов.
😈 Специально для канала @pyway. Подписывайтесь на мой канал в Телеграм @pyway 👈